深入理解计算机系统
信息就是位(bit) + 上下文(使用这些bit的地方,对他们产生不同的解释,理解为一个整数?或者其他)
源程序.cpp
预处理器 预处理过的源程序.i
编译器 汇编程序.s
汇编器 二进制程序.o(机器语言指令,可重定位目标程序)
链接器 最后程序(将相应的部分放进来)
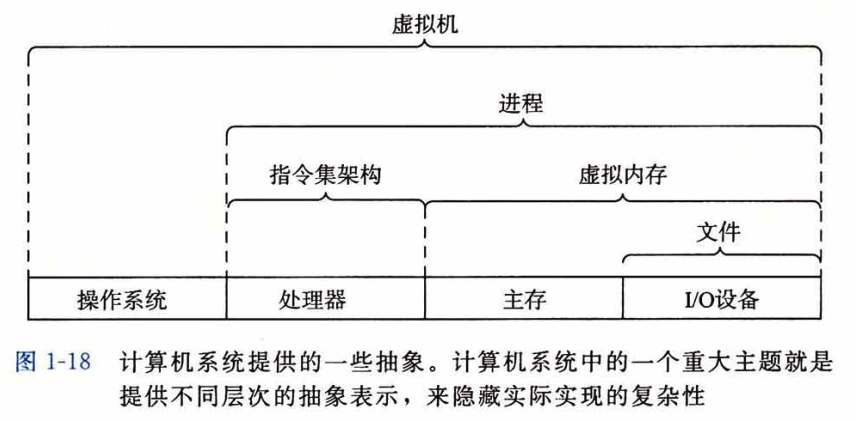
组成:总线,处理器,IO,主存
执行程序的过程中(./hello)
键盘经过处理器(寄存器)存储在主存,主存读辅存程序,到处理器运行(寄存器)输出到显示器。
为了速度,处理器里有cache。 寄存器,l1/2/3缓存(sram),主存(dram),辅存,分布式
L2对于每个核,L3对于所有核
操作系统基本功能:防止硬件被滥用并抽象他们。
系统调用会保存上下文,然后进入内核空间切换上下文,运行完后再出来。
进程是操作系统对一个正在运行的程序的一种抽象
虚拟内存提供了一个每个进程都在独占地使用主存的假象
存储顺序(从小到大):程序,堆→,共享库,←栈,内核虚拟内存
加速比定律
超线程:让一个核心可以同时运行多个线程,因为并不是核心的每个部分都是同时用的,因此提高切换度,就能做到同时运行。
超标量,同时执行多条指令。
SIMD。
无符号不使用补码存储
对于程序看到的地址其实都是虚拟的,是将各种东西组在一起的结果
字长也就是32位/64位是地址的大小,指针的大小。32位能在64位上运行,反过来不行。
一般为了可移植性,不会直接写类型的大小,而是sizeof(T)。
虽然有大小端序和字长的问题,但是ascii码输出则完全不受影响,因为每一个只占一个。
机器不知道源程序。

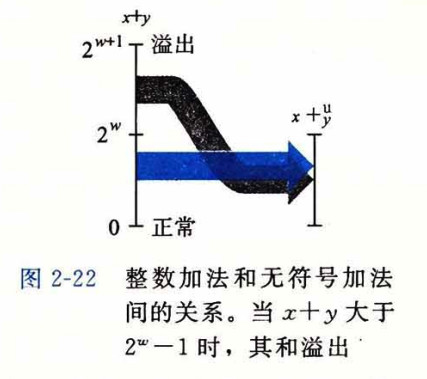
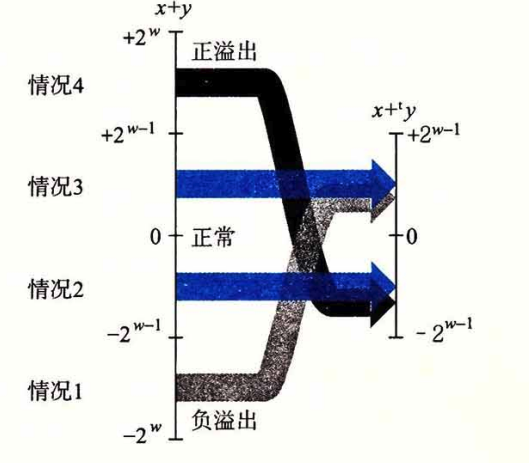
当有符号数和无符号数在一起的时候都会被当作无符号数。
数字转换的时候会先变大小再变符号。往大转换就是无符号补0,有符号就是补与符号位相同的0/1。从大到小就是截断。
乘法很慢,但2的幂只需要移位,那不如直接分解成多个2的幂然后相加。(有符号就先转换成无符号)
但除法并不能推到任意数,只能2的幂。
浮点数的阶码不能全0或全1,这就是规格化的浮点数。而全0就是非规格化的(此时真实值为1-bias,而非-bias,这是为了过渡连续),用来表示0或者0附近的极小数。而全1,有两种可能,后面全1就是无限,否则就是NaN,not a number,比如sqrt(-1)。
阶码用移码表示,即加上bias=2^n-1,这是为了方便浮点数比较时的对齐。
有几种舍入方式,向偶数舍入(<5舍,>5入,对于5舍到最近的偶数,也就是1.25舍入到1.2,1.15也是1.2,对于二进制也类似,在中间值时,即10000的情况,让前面一位为0),去0(就是去掉0),向上和向下舍入。
相较于整数,浮点数没有结合律和分配律,因为精度的问题,这就导致编译器无法优化(不确定优化后是不是就烂掉了)
float/double转int是去0舍入,-3.6→-3,3.6→3。如果溢出会取min/max(最大/最小值,数)
int/double→float也会有精度上的舍入。
x86,最早的处理器8086,8087加上了浮点
i386,32位
Pentium
core i?
%rip,pc寄存器
16个整数寄存器
条件码寄存器
在链接前,目标文件中这些未定义的标识符就还会保持符号的状态:bl _Z5mult2ll,而即便有,也只是一个额标签名而已,直到变成二进制后标签名才会变成具体地址。
一般称2字节为字。
x86架构下,汇编的结尾代表操作的字长。b,1byte,w,l,q,然后是浮点s和l

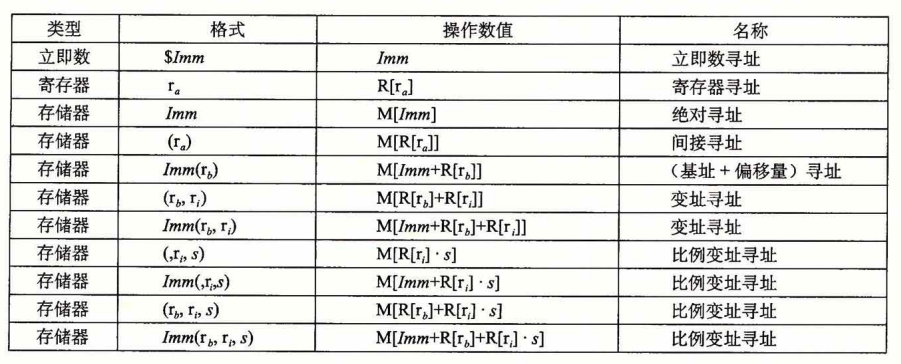
intel的32位寄存器会把高4字节设置为0
mov不能两个操作数都是内存,并且立即数最多32位
为了操作64位立即数,要使用movabsq。但目标只能是寄存器。
movz(零扩展)/s(符号扩展)源大小(b/w)目标大小(w/l/q),但并不是全有,所以需要一些其他指令中转。
cltq将eax符号扩展到rax。
rsp存储了栈指针,push和pop会自动更新rsp,并将操作数存到栈中。
局部变量也是存储在栈的,当函数开始的时候,就会将rsp的内容存储到bsp中作为当前函数所有局部变量的基地址,然后根据局部变量总共要分配的量手动去调整rsp,也就是减rsp,然后,每个局部变量就会在这一段新的栈空间中,可以通过(基址+偏移量)寻址立即获取,也就不用忍受栈的麻烦了,当结束的时候再将rsp收回来。而bsp再函数一开始的时候实际存储的是调用者的地址,因此,需要在一开始先推入栈,最后pop出来就可以ret了。
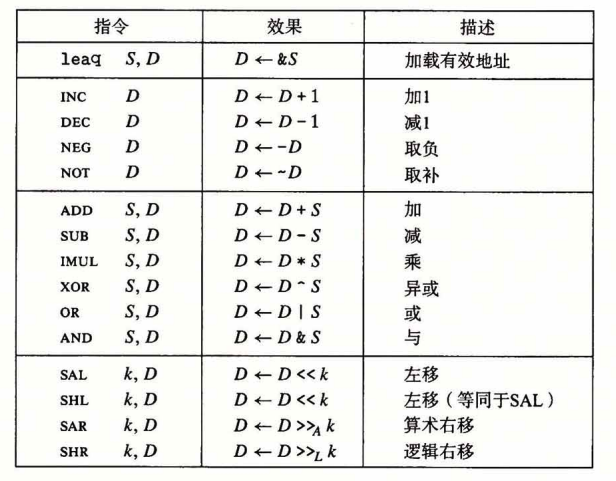
leaq不止能取地址,也能进行一些计算,前面对于地址本身就有一些计算,就可以借用leaq来取到这个地址计算的结果。
右移也有两种,一种是补0,一种是补符号位。
在这里也不管有符号还是无符号,因为操作起来都一样。
对于机器来说,它才不管这里存储的是什么类型,你只要调用正确的汇编命令就好了,而这个汇编命令的决定是由编译器这个知道类型的人来做的。

通过rax和rdx的拼接可以实现128位。

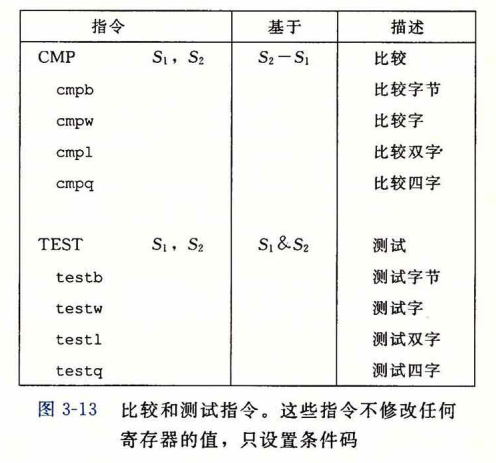
根据这些条件位,有三种处理方式。
- 设置值

- 跳转
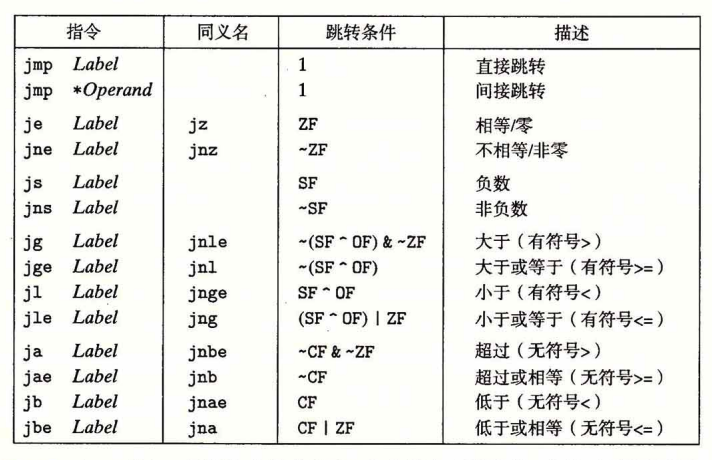
当进行相对跳转的时候,虽然汇编里写的是jmp 某个特定数字,但最后到机器码中就会变成jmp 数值-下一行的pc,这样就算整体的程序的位置改变了,也不改变它的相对位置。跳转到下一条指令位置加上这个偏移量。
- 条件传送
上面这种被称为条件转移,满足条件就转移,但是效率低下(因为会有预测失败惩罚),因此也可以使用条件传送来替代。
条件传送就是当条件满足的时候就进行mov。
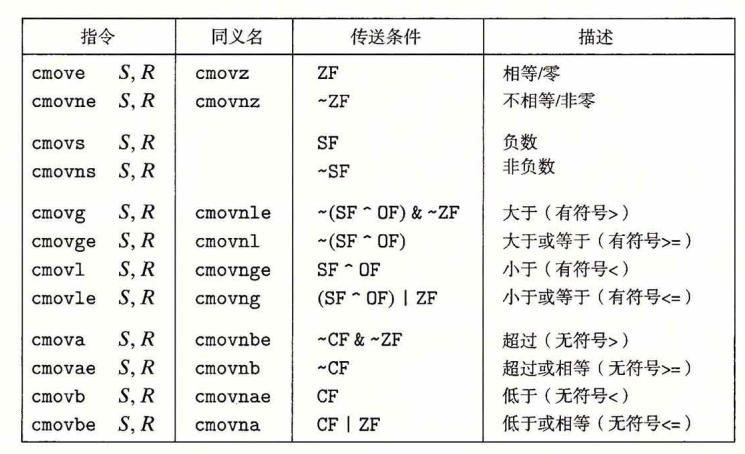
但是条件转移也并不总是好的,它的实现方式是在一开始就执行条件成功和失败的两种情况,然后根据最后的cmp结果来将其中一种情况作为最终的情况。但当有的时候条件内部的执行是依赖于条件本身的时候,比如在指针不为空的时候对指针解引用之类的。并且由于两个都要执行,所以可能还慢于条件转移,编译器会进行权衡。
三种循环都可以用条件转移实现,do-while,while,for。
感觉还是应该多用switch。
当switch的选项较多的时候,gcc就会启用跳转表,通过偏移量和数组来快速确定跳转位置。o(1)。而ifelse要on。
当进行函数调用的时候,受限尝试将参数放进6个参数寄存器中,如果放不下,就放到本函数帧的栈上,然后最后放上返回本函数的返回地址。而对于被调用者来说,它要保存之前p的所有寄存器状态(如果它需要更改这个寄存器的话,就需要在函数开始push这个寄存器,在最后pop出来,但如果不更改的话就不需要),然后分配自己的局部空间,然后自己处理,处理完后按返回地址返回。要注意的是,多出来的参数和返回地址都不是在被调用者的帧中的,而是在调用者的。
call就是压返回地址(调用函数的后面一行),然后设置被调用者的地址为PC。
ret就是弹出地址,然后设置地址。
call的对象可以是标识符,也可以是一个操作出来的地址。
额外的参数要按8字节对齐。通过正数偏移量rsp去取这些参数。
rsp的变动会自动释放对应的区域的栈。
有的时候编译器会自动将数组的index的变化优化为指针上的加减。
结构体中的每一个元素就是一个偏移量而已。
union可以极大的省空间。数据对齐能够提高程序速度,但存储空间更大。
由于数组不检查内存范围,因此当超过访问的时候也不会出问题,但是实际上会访问到不该访问的内存。
这种可能会导致各种攻击。因为能够去访问不该被访问的东西。可以通过多种方法缓解:
- 地址随机化,每次都加载到不同的内存空间。
- 在栈的局部变量部分和其他部分之间插入一段内存空间,空间的值是金丝雀值,如果这段被访问就立即终止程序。
- 对于内存进行权限控制,比如让一段部分只是可读的但是不可执行。
对于变长的数组,可能就不知道栈上要分配多少长度了,而这本身应该要在编译的时候就确认下来。为了解决这个问题,除了rsp指向栈顶,还会用一个rbp指向帧底,来动态的控制长度。
浮点数也有对应的16个寄存器。64位,分为两个长度。
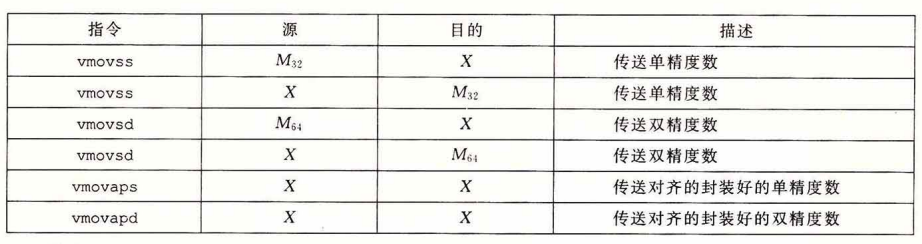


参数传递的时候浮点数也会放在浮点数寄存器中,分别按顺序放。
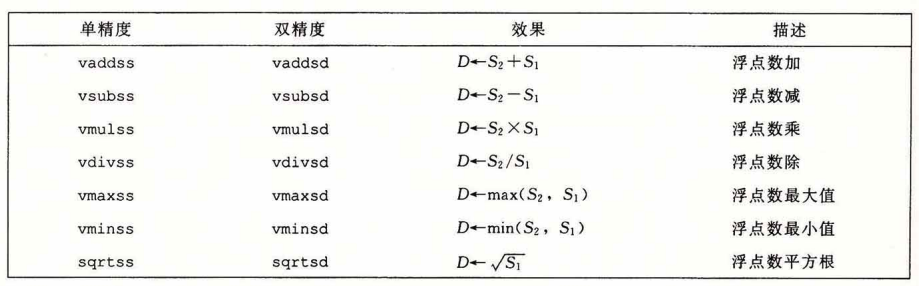
立即数不能指定为浮点数。因此需要在内存中先设定这个常量然后再读出来,一般通过两个部分组成,一半作为高4位一半作为低4位。


实际上现在risc和cisc都已经开始融合了,你中有我,我中有你。
汇编除了汇编命令,还有很多汇编伪代码来指定一些东西,比如程序开始位置,对齐等等,这些会以点.开头。
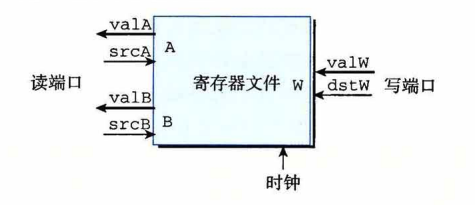
取指,译码(同时还会从寄存器读操作数),执行(计算),访存(内存),写回(寄存器)
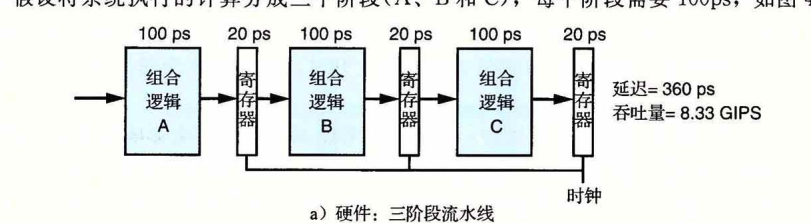
这才是真正流水线的样子。每经过一段逻辑,要对所有寄存器存储一下,这样才能真正的实现并行,每次从寄存器中出来,再回到寄存器中,互不干扰。
不同层级的寄存器可以完全不同,只需要存需要的就可以了。

总共有两种相关性:数据相关和控制相关
但数据相关中只有寄存器会产生冒险,因为寄存器的读写不是同一个环节完成的。
而对于这种,有几种方法解决。
- 暂停:如果发现当前流水线中正在处理3,4步的会更改我指令的操作数,那么就插入nop进行阻塞。
- 转发:但这样还是太慢了,阻塞太久了,不如直接从3,4步把算出来的值直接送到驿码这里。(但是要求这个3,4步执行的事件早于或等于译码的时候)
- 加载/使用:但如果晚于译码,那就将暂停和转发结合。
而对于控制冒险,对于ret来说,就在ret后等待直到ret写回寄存器的同时取出它写回的返回地址进行取指就可以了。而对于跳转来说,但到达第3步的时候,也就是执行的时候,就能判断到底是否要跳转了,而这时候前面预测的指令才刚刚执行完1,2步,还没能对整个程序造成任何可见的影响,因此直接让他们后续终止,立刻开始新的一条就可以了。
对于异常处理:只处理最深的那一条异常,对于预测产生的异常如果后续发现预测失败就忽略,当发现异常后要立刻停止任何命令更改可见状态。
实际上暂停和插入气泡是有区别的,暂停时保持不变,一直输入相同的内容,而插入气泡则是将输入改为nop。气泡是因为比如预测错误,那这些指令就不能要了,因此要填入气泡。而对于数据相关,指令并没有改变,但只是要延迟而已。
并且实际处理的时候不能将这些特殊情况都单独处理,应该要假设他们可能会同时发生,对于每一个部分如果产生不同的操作,那么就需要进行特殊处理。
通过对于每种不正常的流水线情况都计算cpi就能估计总体平均的cpi。
对于较为复杂的指令,一般就不使用流水线来处理了。而是发射到专门的处理单元中处理。
编译器只能进行安全的优化,而不能假设你程序中蕴含的一些隐藏的特性。(比如两个指针可能指向同样的位置)
CPE:每元素周期数,每个元素处理所花费的周期数
提取循环中的不变量。使用临时量,减少读写。
在优化程序性能的时候,应该找到关键路径(也就是耗时最长的不能并行的这些操作),对这条关键路径进行优化。
可以使用循环展开进行优化。并且,每一轮之间的同样适用的元素也是会产生数据依赖的,就不能并行,就应该在多个不同的变量上进行操作进行循环展开,最后在统计在一起。
有的时候运算执行的先后顺序也会对于数据依赖产生影响,可以通过调整括号来避免。
但是无限增加循环展开的程度也不行,每增加一个临时元素就要占用一个寄存器,如果超过寄存器数量,就产生了寄存器溢出,就会放到内存上去了,导致速度下降。
通过修改程序让程序更容易被优化为条件传送可能能够优化原本的条件转移。
避免产生内存读写相关。



局部性:循环越小,迭代越多,访问的变量更相同,步长更短
全相连因为要大量并行匹配所以昂贵,因为产生冲突的可能大大减少。
主存地址:行标记,组标记(全相连不需要),块偏移
cache地址:组标记
有三种链接,编译时,加载时,运行时。
编译器和汇编器生成可重定位目标文件和共享目标文件(加载时或运行时链接),一个目标文件就是存储目标模块的文件。
链接后就会变成可执行目标文件。
目标文件格式:elf/exe/mach-o
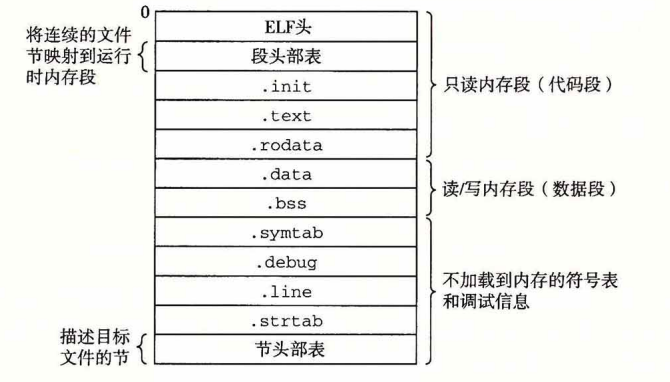
一个ELF的文件格式:ELF头(包括一些编译这个文件的信息),各种信息的节(.text,编译的机器代码,.rodata,只读数据,.data,已初始化的全局变量和静态变量,.bss,未初始化的全局和静态便令,(实际上只是一个标识符,没有任何数据),.symtab,符号表(只包含函数的符号,不包含局部变量),.rel.text,需要更改(链接)的.text中的位置列表,.rel.data,需要更改的全局变量的地址,.debug,调试信息表,.line,行号信息),节头部表(后面每一个节的位置和大小)
感觉链接就是处理.rel这一部分。
static全局变量/函数只能在本源文件中使用。不const的全局变量默认时extern的,可以重声明。
实际上对于全局的函数或者变量,static就是只能被本文件,extern就是能被别的文件。
符号表中的内容:本文件能被别人引用的符号,本文件引用的别人的符号,不能被别的文件引用的本文件符号

符号表每一行数据数据。
每个符号最后都会对应到某个节中,也就是这边的section。
有三个特殊节,COMMON,UNDEF(未定义),ABS(不需要重定位)
COMMON 未初始化的全局变量
.bss 未初始化的静态变量,以及初始化为0的全局或静态变量(初始化为0后就说明这是强变量,也就不用交给链接器ld去决定了。
c++要求使用不同的符号,而对于函数重载,它的名字就会和后续的参数连起来形成一个字符串也就达到了不同。
当面对多个同名符号时,最多只允许有一个强对象,并且会选择这个强对象。如果有多个弱对象,那就随机选择一个。
函数和已初始化的变量是强对象。为初始化的为弱对象。
extern后的必然是弱对象。因此实际上一个变量可以以不同的类型多次定义,而最终会随机选择。
如果是正常情况下,我直接将一个库编译为一个目标文件,当我把它链接到我的程序上时会将全部内容塞到我的程序里面。最终导致每一个程序都会包含一个库。
而如果我要更改这个库,那么每次都要全部重新编译。那么一个简单的办法就是把它分成多个目标文件进行编译,但还是没解决重复包含的问题,而且没必要的也包含了。
因此静态库就被提出来,只会复制被引用的部分。
静态库以一种称为存档的特殊文件格式存放在磁盘中。存档文件是一组连接起来的可重定位目标文件的集合,有一个头部用来描述每个成员目标文件的大小和位置。
但是静态库链接的方式很抽象,按照gcc 文件排序的顺序,它只会给前面的可重定位目标文件提供符号。还是cmake好。
而到目前为止,只是目标文件中的所有符号找到了自己的符号引用是谁。
接下来要将这些目标文件合并为一个可执行目标文件。
将所有输入模块中的相同段合并,并确定地址。然后根据重定位条目更改所有符号引用的地址。

重定位条目。这些在编译为可重定位目标文件的时候就生成了。已初始化的在.data,为初始化的在.text。这里的type代表这个重定位的数据代表着什么,该如何重定位,相对的,还是绝对的。addend有的时候作为一些相对定位的偏移量。
之所以在生成的时候不能定位是因为不知道addr(symbol)的值,而现在链接的时候就知道了,因为所有的都合并了,确定了地址。
最终生成的可执行程序。
会额外增加一个入口点。去掉.rel,因为已经链接完了。
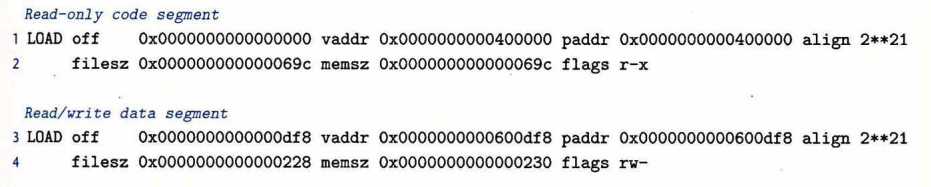
一般会生成两端,一段读执行,就是程序段,一段读写就是数据段,vaddr就是虚拟地址,paddr就是物理地址,一般要求off%align=vaddr%align。
程序复制到内存:加载,调用exec就是加载。将自己这个程序给清空,然后复制对应的过来,但实际上并不是全部复制,而是根据缺页中断自动复制。开始是先到_start函数,然后调用__libc_start_main,然后再调用main,结束后__libc_start_main会处理返回值。
为了避免更新库后需要显式链接,以及常用函数在多个程序中的冗余,就是用动态链接库。
动态目标/库由动态链接器来在运行时或加载时自动链接。
-fpic生成与位置无关的代码。对于动态链接库,在编译期链接的时候仅仅加入了一些重定位和符号表信息,直到加载的时候才将代码和数据放进来。加载的过程中,如果发现了.interp节,那么就将动态库重定位到内存后(位置就不会再变了),重定位程序的所有引用。
也可以在运行时动态链接,dlopen(动态库路径,flag(立即加载/使用时加载等)),返回一个句柄。dlsym(动态库句柄,符号名)返回符号地址。dlclose(句柄)卸载动态库。
fpic(position independent code)。共享库的编译必须总是启用fpic。
如果不开启fpic,那么它在内存中的加载位置就是固定的,这在现代显然难以想象,所以现在都是默认开启fpic的。
因为我们希望无论动态库在内存的哪里,用这个动态库的都能正确的使用。而对于本目标文件里的符号来说,都是pic的,因为相对位置不变。
其实很简单,对于变量,就维护一个GOT表(global offset table),所有的全局变量的符号都会在GOT总有一个表项,对于本模块的,就直接有一个固定的相对偏移量就好了,这在编译期就能确定,而对于其他模块的就先空着。在加载的时候,就会调用动态链接器,而动态链接器作为加载过所有模块的,自然知道其他的在哪里,就会将真正的地址加载到GOT表中。
而对于函数,在进行call的时候,会进入过程链接表(PLT)中,这个PLT会间接的去访问GOT去查询真正的函数的位置,查询完后保存在GOT中,以后就不用再查了。相较于变量是加载的时候就绑定,函数是延迟绑定的,即当第一次调用的时候才会去查询。
所以对于全局函数的使用,都会在第一次比较慢。
所以现在一个程序里只有相对地址而没有绝对地址了,编译期间的重定位也只是重定位这些相对位置的值。原本可能是空的。直到加载的时候才有绝对位置。
库打桩(一般是动态库):通过某种方式在编译/加载/运行时替换掉某个原本的函数。
编译期间链接替换函数的库的时候用-I指定搜索路径来让它先查找到替换函数所在的库。
在链接时-Wl将后面的参数传给链接器,—wrap,函数名,就会在链接时将f符号链接到__wrap_函数名上,而__real_函数名链接到真实的f函数上。
在运行时只需要通过LD_PRELOAD环境变量设置为假库,它就会在查找符号的时候优先查找假库的符号,而为了调用真库,一种是运行时链接,一种是额找更深一层的函数或者函数别名。

异常处理:中断然后根据异常表调用对应的异常处理程序,处理完后要么回来继续,要么跳过中断的这条语句继续,要么终止程序。异常表每一行存储着一个异常处理程序的地址,通过异常表的基址和编号即可求出地址。作为一个特殊的系统调用,在内核态运行。既有操作系统定义的异常,也有处理器定义的。
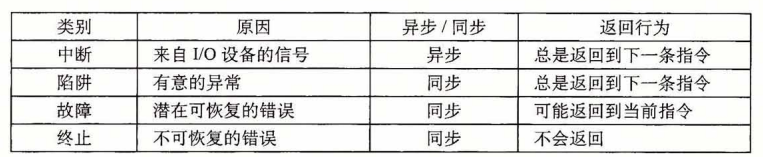
陷阱就是系统调用(参数只允许通过寄存器传递)。中断I/O。
进程:虚拟的处理器独占,虚拟的私有内存空间,上下文切换(保存,切换,读出)用户栈,内核栈寄存器等等。
系统调用都应该要检查返回值。


pause函数,进程睡觉直到收到一个信号。
在exec的时候除了传递参数,还可以传递环境变量。接受者用int main(argc,argv,envp)来接收。也可以通过getenv(名字)来获取,setenv(名字,值,是否覆写)来更改,unsetenv来取消。
eval(command)用来评估是不是内置命令,如果是就直接运行。对于shell来说,如果不是后台程序,就需要fork一个子进程并wait它完成。
在终端界面的ctrl+c/z都是给命令行前端进程发送一个全体信号。
信号默认阻塞同类型的信号。处理程序中最好只调用可重入函数以保证处理程序的可重入性。阻塞信号。由于每一个信号最多pending一个,因此要尽快处理,避免遗漏信号。
系统调用也可以被中断,这个时候就会返回EINTR,需要手动重新调用。当主进程和信号处理竞争的时候可以通过设置屏蔽来避免。
通过sigsuspend可以用暂时设定的mask屏蔽自身并挂起。
通过setjmp和longjmp可以无视程序位置随意跳转,很像throw的概念,setjmp为跳跃回来的位置,longjmp进行一次跳跃到对应的setjmp。setsigjmp和longsigjmp也是类似,不过是从信号处理函数中跳出来。
strace实际上是显示进程和每一个子进程进行的所有系统调用。
程序提供给cpu的永远是虚拟地址,再由mmu转换为物理地址。物理地址就是磁盘上的一段存储空间。被分割成页。有的未被分配,有的未缓存,有的已缓存(进入内存)。DRAM缓存永远使用全相连,因为不命中代价过大。并且采用写回法。
通过一个常驻主存的页表来记录虚拟地址和真实地址的对应。(每一页都很大)
但实际上每一个程序都有一个自己的页表,也就形成了自己的虚拟内存空间。因此实际上程序本身可以放在虚拟内存空间中的任何位置(所以实际上如果不开启fpic那么地址都还是绝对地址,ASLR不需要fpic,只需要将它开头加载到随机的基址上就好了,里面的地址加上一个这个偏移量就好了),因此不需要fpic,但是共享内存复制进来的时候可能就不能放在固定位置上了,需要fpic,而为了统一,因此即便不需要fpic也统一开始用fpic了。通过虚拟页表指向同一个真实地址就实现了共享。
通过程序页表就可以进行权限管理,内存保护。
整个流程:处理器产生虚拟地址,转换为PTE地址,获得物理地址,去磁盘获取。
如果与cache结合:处理器产生虚拟地址,问mmu,mmu问cache有没有pte,没有就去内存要,否则就返回mmu pte,根据pte获得addr,问cache有没有addr之后相同。
但现在职责已经分离了,专门有一个cache叫tlb来缓存页表,cache中只缓存真实数据(好吧,也可能缓存PTE)。但为了让虚拟内存尽可能大,页表也就会随之增大,导致内存装不下。因此引入多级页表,只将最常用的留在内存中。进程切换的时候实际上也只是切换了页表基址而已,但是tlb,l1,l2之类的cache是完全失效的。tlb也可以是多级的。
所以整个映射关系是程序虚拟内存中的一部分存储在物理内存上,物理内存映射了一部分存储虚拟空间的页。如果发现在内存中也没有,就是缺页中断咯,然后这个时候会把程序给的虚拟地址在外存中进行定位。
在程序的虚拟内存的内核虚拟内存部分,一部分记录了一些运行程序的信息,一部分是内核的程序和数据,还有一部分是映射了内存。
程序的虚拟空间也可以直接映射磁盘对象,一种是映射具体文件,那并不会在内存中申请空间,直到真正使用到的时候才会弄入内存,也就是缺页。另一种是匿名申请一段空间,设置为全0。大概就是动态内存分配。
实际上也正是通过映射具体文件的方式和磁盘产生了联系。
但一旦一个页面被初始化了,它要么呆在内存,要么呆在磁盘的swap空间,不可能再出去了,除非被显式关闭。当超出之后就开始kill程序了。蚌埠住了,macos会自动扩容swap。
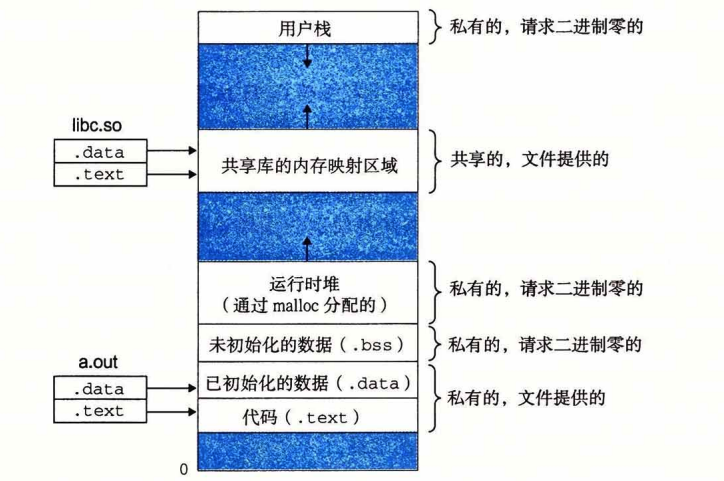
通过mmap可以手动映射。动态内存分配就是与磁盘对象产生联系的第二种方式。有一个brk指针指向堆顶。有两种分配方式,一种是显式,就是c++这种,另一种隐式,就是gc。除了malloc之类的,也可以直接调用sbrk来brk指针。
mmap也会从内存中进行分配,但单位是页,所以就没什么好思考的。而malloc分配则是不按大小的,所以需要内存分配算法。
分配内存空间的时候会产生两种碎片。内部碎片:分配的时候也要对齐,对齐时就会额外申请空间来填补这一部分,这一部分就是内部碎片。外部碎片:加起来能够容纳。
但这块内存上还是需要一些数据结构来管理已分配或者未分配的内存。一种就是,每分配一块,就让它是一个完整的数据结构,头部有长度和一些管理信息,后面是具体的空间。这样就可以从前往后按照头部的长度编译了。当找到一个可用内存块后,可以分割,也可以不分割。
当一段空间释放后,可以选择立即和附近的空闲块合并,也可以推迟。但是立即合并可能导致紧接着又切割了,所以一般都会有一定的延迟去合并。
但是合并的时候合并后面一块很方便,但合并前面一块并不是很方便,因为不知道前面一块的长度,因此可以给每个块的倒数一个字节里额外记录长度和状态。
另一种就是显式的一种双向链表,有效荷载里额外维护一个前指针和后指针。但即便是用指针串起来了,它的合并仍然是o(1)的,因为,它要合并的还是它真实存储位置上的。
维护链表的方式,也就是链表的排序方式有很多种。链表的排序会对最终申请的内存空间产生很大的影响,就比如首次适应下使用按地址排序就会内存利用率更高,但是释放比较慢。
但这样随着块的增多,链表会越来越长。因此也可以按块的大小存储在不同的链表中。每个链表存储大小在a-b范围内的所有块。简单分离存储就是在最开始分配好大小放在不同的链表中,但分配的时候不分割,不调整,这就会导致内存利用率低。而分离适配就是会额外进行分割,并放到对应大小的链表中,内存利用率非常高(不知道为什么),gcc的malloc就是。
还有就是伙伴系统,每个块都是2的幂,效率很高,但是内部碎片也会很高,2的幂的差值太大了,只适合特定的任务群。
对于垃圾回收,所有引用比如栈,或者寄存器都会到这个分配的内存有一条有向边,当发现一个内存没有任何外部的节点指向它之后,就可以说是垃圾了,就可以释放了。
每一轮都对所有根节点mark一遍,第二遍扫描的时候如果没有被mark就可以被释放了。
这个操作将在malloc发现没有能够分配的空间的时候进行。
但是这里很重要的一点是要识别内存中存储的是不是指针,但对于c来说并不能判断,内存里是不存储信息的,一个对象可能是指针也可能是其他类型。因此只能保守的进行回收。
文件读写不一定会映射到内存中,内核还是进行了一些操作,只是维护了一个数据结构,然后将对应的部分复制到缓冲区。
硬链接和软连接就是shared_ptr和weak_ptr。
读写要缓冲是因为IO很慢,尽量一次性多处理一点。
可以用stat和fstat来读inode内容。
可以用open/read/closedir来读目录。
每个进程持有一个打开的文件描述符表,内核共享一个所有打开的文件表,维护比如当前有几个人打开。文件表指向inode。但也可能有指向相同inode的文件表,因为还要维护读写位置,这个每个进程可能不同。
dup实际上就相当于文件重定向。
对于流I/O,如果要同时输入输出,要刷新缓冲区。
多线程尽量先进行局部计算,再进行统一。
可重入不是指线程安全,而是线程安全中的子集,代表没有任何共享变量。