计算机网络
网络层及以下都是内核空间。
端口和每一层的类型一样,都是用来表示它上面一层使用的协议类型。
arp在局域网内一段传输主机之间知道互相的ip的时候广播arp请求询问对方的mac地址并由对方也已arp应答。包大小46,但填充到64(以太网传输要求)。
dns(应用层但直接用ip服务)就是类似于网上有一个分布式维护的域名和ip转换的数据库,所谓的dns服务器就是其中的一个服务器,里面的数据是动态更新的,如果发现查询的不存在且开启递归,那么这个服务器也会去问别的dns服务器。
socket不仅于tcp/udp,通过socketopt还可以使用其他的协议。
IP协议无状态(如果发多个报文段,不管整理,标识符只是用来分片的),无连接(每次都要输入IP),不可靠(尽最大努力)。
IP会分片,因为最大1500的长度。
tcp,字节流,面向连接,可靠。但是发送不是一个一个发的,我们将数据通过write放进缓冲区的次数与发出的tcp的个数不一定一样,通过read读到的个数和tcp的个数不一定一致,有粘包和半包的问题。
udp就是一个数据包就是一个信息。如果缓冲区不够还会直接被截断,接收不及时还可能直接没掉。

time_wait状态是为了可靠的终止tcp连接,一种可能是超时了,需要重发什么的(并保证不再存在失效的报文段),另一种是如果关的早,那么自身客户端端口关闭了就可能被其他使用,导致和服务端建立错误的连接。
半连接,不能回消息或者异常终止就会发RST。
服务端一般会延迟确认(将确认放在数据一起发),而客户端不会。
但这样会产生很多小包,nagle算法要求任意时刻只能有一个未确认的包在传输。
正向代理就是客户端主动指定代理服务器,然后向他发请求让他转发,vpn就是。
反向代理就是请求同一个服务器,但是这个服务器表现的像一个真实的服务器一样,来将请求转发给可能多个服务器,一般网站都是这么搞的。
透明代理只能设置在网关上。
小端序是反的(主机),大端序是正的(网络)。
socket(协议族,传输类型(数据包/字节流/不阻塞(但这个不阻塞不是指收到的这些连接的fd不阻塞,而是这个监听的fd不阻塞,也就是accept不阻塞,但是read,write还是阻塞的)等等),0(指定协议,但一般默认))
bind(fd,地址的指针,地址的长度),地址可以通过getaddrinfo获取,进行转换。
然后listen(fd,缓冲区大小)
这个时候完成三次握手。
accept(fd,接收到的连接的地址的指针和,长度),不在乎握手完后的状态,只是从缓冲区中取一个出来。
connect(fd,服务器的地址的指针和,长度)
close只是将fd的引用计数-1,当fork的时候会自动让子进程多获得一个引用。
shutdown则是直接关闭fd,可以分别关闭读写和一起关。关闭读会清空读缓冲,关闭写会将写缓冲的全发出。
读写的时候0代表关闭连接,-1代表阻塞或者其他错,得靠我们自己来判断要读多少。
recv和send就是比read和send多了一个flag参数,这个flag可以指定不阻塞啊,处理紧急数据啊等等
紧急数据接收到的时候只会将最后一个字符认为是紧急数据,而前面的会跟着正常数据走。
recvfrom和sendto就是多两个参数,表示对方的地址指针和长度,作为udp的send和recv,但是如果设置为面向连接,那么也可以省略。
recvmsg和sendmsg则是一套通用的接口,支持分散存储的读写。
一般通过IO复用来判断现在是不是有带外(紧急)数据,然后调用对应带flag的读写。

对于fd设置的sockopt中的一部分设置同时也会对accept返回的fd代表的socket生效。
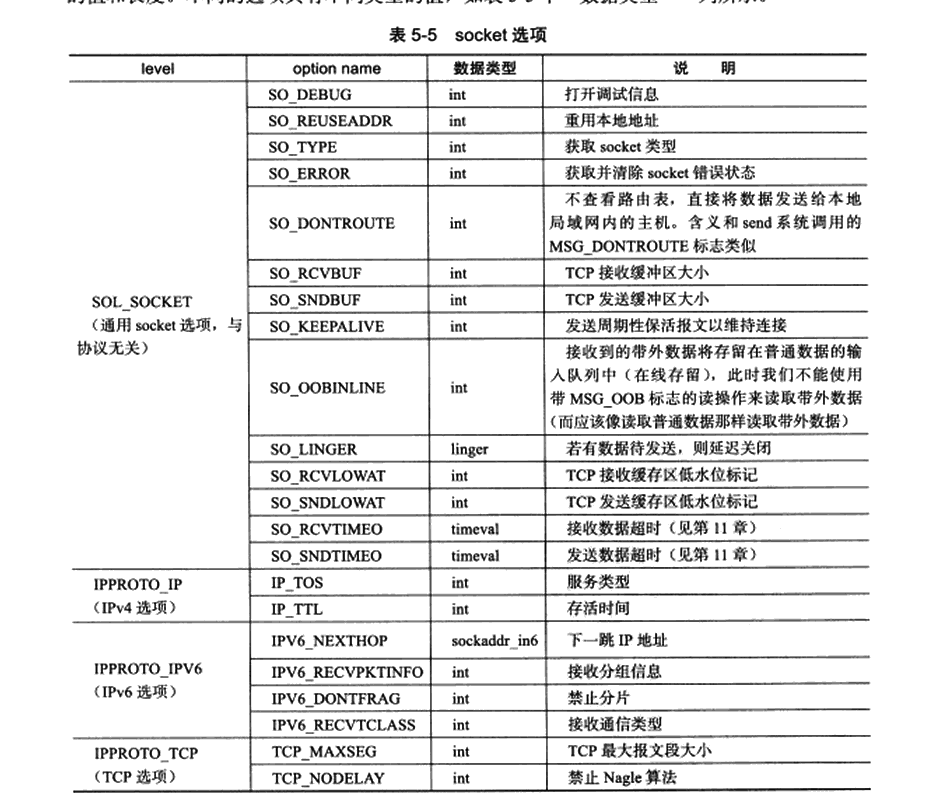
reuse_addr选项就是能够无视time_wait而去重用。
低水位标记就是什么时候去通知多路复用。

可以通过gethostbyname/addr来查/etc/host,也可以通过getserbyname/port来查/etc/service。
getaddrinfo则是统一了上面两个,getaddrinfo(主机名/ip,服务名/port,提示(针对于返回的结果进行一些设置,比如是否是服务端啊,如果是的话就应该设置为通用的之类的),addrinfo* 结果)
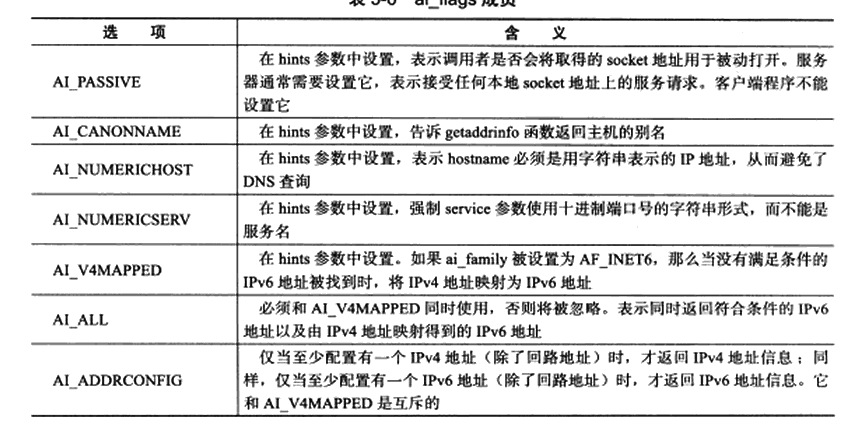
比如这里的ai_passive就是要求返回的ip是一个通用的,因为对于这些要求实际上也是在ip的类型上体现的,比如说设置为0.0.0.0。
getaddrinfo会分配堆内存,需要通过freeaddrinfo来销毁。
管道,pipe(int fd[2]),fd[0]只能读,fd[1]只能写。如果对fd[1]的引用为0,这fd[0]读到eof,即0。如果fd[0]的引用为0,则fd[1]报错。和tcp一样是字节流。
socketpair也能创建管道,用unix本地协议,并且创建出来的是可读可写的。
dup,复制一个指向同样文件的fd。取最小能取到的fd。dup2则是大于参数的最小的。复制所得的不保留标志。

writev和readv就是同时往多个内存读或者写。
sendfile(输出fd,输入fd,输入offset,字符数)。要求输出是socket,输入是普通文件,专门为网络文件传输服务。(零拷贝,因为是在内核中做的)
而一般情况下都会多两次拷贝,到用户空间和离开用户空间的拷贝。
mmap(指定内存开始地址(也可以不指定),长度,权限(rwx无权限),类型(共享/私有/与文件无关/等等),fd,文件偏移量)
splice,零拷贝(输入fd,输入偏移量,输出fd,输出偏移量,长度,flag(基本无用)),不能自己拷贝到自己,需要靠一个管道中转。
tee,零拷贝,管道到管道(输入fd,输出fd,长度,flag),不消耗输入fd中的数据。
fnctl,复制fd,获取/设置 fd标志/状态标志/信号/管道大小
一般服务器都会有日志,以守护进程运行,以非root用户运行,有配置文件,记录pid。
日志:linux的日志实际上不是直接输出到程序,而是跟Linux上运行的一个守护进程rsyslogd通信,rsyslogd才输出到日志。
通过syslog(优先级,内容,…)来通信。可以通过open_log来设置一些默认东西,并通过setlogmask来设置掩码。
一般进程会有两个uid,一个uid,即运行者的uid,一个是euid,有效uid,代表这个程序的有euid的权限。一般用来获取root权限,这样就能让普通用户也能运行一些部分需要root权限的程序,并且这些权限也保证不会拿这些权限干坏事,而为了获取root权限,就必须要给这个可执行文件设置suid,也就是chmod +s,而这是需要sudo权限的,因此权限上也是安全的。同样也有egid。
而进程组pgid就是同一管理进程嘛。以上这5个东西都可以在程序中get和set。
会话比进程组更高一个级别。一个会话可以有多个进程组,一般跟终端绑定。当终端有什么操作的时候都会反应到这个会话上的所有进程上,比如发个信号之类的。因此为了保证不跟终端绑定,就可以用setsid来创建新的会话。这个调用者就会创建一个新的会话,会话里有唯一一个进程组,首领是它。会话sid实际上就是首领的pid。
set/getrlimit可以设置程序的各种资源限制,其实和ulimit差不多,但是如果没有root权限,那么就不能增加,只能减少。一般有两个值,软限制和硬限制,硬限制是软限制的上线,超过软限制就会发送信号。
getcwd获取当前目录,chdir设置工作目录。chroot设置进程根目录(进程能看到的最根的目录)但是仍然能访问之前打开的fd,这个命令需要特权。
一般要成为守护进程,需要进行成为子进程(脱离终端)(fork),创建新会话,切换工作目录到根,关闭三大标准流重定向到/dev/null来进一步脱离终端。之所以要重定向是因为如果在关闭的状态下进行标准三大行为就会报错。
linux也提供daemon函数来做到上述流程,daemon(是否切换工作目录到根,是否重定向标准流)。

reactor就是IO复用,proactor就是异步I/O。可以用IO复用模拟proactor。
reactor读写在工作线程,因为是半同步阻塞的。(读写都是工作线程在干)
proactor则不在,在异步接收的部分,因为是异步的,所以工作线程只需要处理逻辑就可以了。(读写都是异步I/O在干,也就是内核在干)
模拟的就是将读写放在异步的部分,但是是用IO复用来做。也就是我实现的这种,虽然我的工作线程其实也放在了同一个线程中。(读写都是epoll在干,主线程在干)
半同步半异步(不是指异步I/O,而是通过事件驱动,而非立即进行),半异步指的是把收到的任务全部扔进队列里,工作线程池自己从里面一个一个取出来处理(同步的)。
半同步半反应堆,就是将异步I/O替换为I/O复用。
更高效的话就是主线程只管accept,accept完就将fd扔队列里,工作线程自己抢,然后将fd注册到自己的epoll里,后续的这个fd都由这个工作线程来处理。
而半同步半反应堆则是每一个客户的每一个请求都是由主线程来负责,工作线程每次只处理一个来回的请求。而高效则是所有来回都由工作线程来负责。
领导者追随者就是,领导者监听,然后当听到一个请求后就去处理(也可能指定其中一个fellow去处理),并将监听的活交给其中一个fellow。但一个线程处理完成回来并发现现在没有领导者,就成为领导者。
池就是将动态的资源先全部静态的申请。
能不拷贝就不拷贝,去使用零拷贝的函数,共享内存也由于管道和消息队列。
减少锁和切换。
select注册起来是直接传入一个类似于bit_seqence的东西,设置为1代表监听,返回发生的个数,但不知道是哪几个,会将bit_sequence对应的位置设置1,你需要自己查,并且分别查,读,写,异常是三个队列。
poll则是将select的事件进行了统一。
但都是只有LT模式,并且都是轮询,比较慢,而非像epoll是计时器回调。
除了关闭连接read和write都会返回0,出错回返回错,能读能写返回个数,还有就是connect的时候超时会返回,accept时候会返回。
LT水平触发,只要能触发,就会一直触发。ET,只触发一次,如果这次不处理,以后就无了。因为要一次处理完,所以要while。并且ET的情况下一定要非阻塞,否则以后就会一直阻塞。
ET情况下,处理进来的数据的时候也有可能又有新的数据到来,因为网络并不是一个一读一写的过程,比如http2就不会,但是http1.1还是会一读一写的。有的时候我们要保证一个socket都是由一个工作线程来处理,这个时候我们就可以设置EPOLLONESHOT让它暂时屏蔽后面的,直到我再次调用epoll_ctl设置epolloneshot,才会又接收一个请求。
但活动较多的时候,则效率不一定epoll高。epoll适用于连接多但活动不多。
带外数据一般也会算做一个error信号,可以与普通的进行区分。
connect一般是不能非阻塞的,但是,当使用非阻塞的时候,并且没有立刻建立连接,就会返回一个专属EINPROGRESS错误,后续监听它如果发现可写就说明连接建立了,就实现了非阻塞。但这不一定能成功,得看实际机器实现情况。
信号,kill(pid,信号)pid为0时发送给本进程组的其他进程,-1发给所有除init之外的进程,只要有权限,-pid发送给组id为pid的进程组。在c++中一般通过std::signal(信号,处理函数)来注册。处理函数也可以是两个预定义的宏SIG_DFL(默认)和SIG_IGN(忽略)。
一般为了避免让信号迅速处理完以不屏蔽后续的信号并且避免一些竞争状态(因为一般信号处理都是在一个新的线程上处理的),一般信号处理只是将接收到的信号放到管道中,在主循环中监听并一起处理。
sigaction是定义在posix中的,并且功能更加全面。同时能屏蔽信号,设定中断后的重启设置等等,并且是原子的,处理函数也可以更复杂。signal这个东西本身就是当收到信号的时候立刻从收到信号的这个线程中断叉出去,然后同步处理,然后返回。
信号是整个进程都会接收到的,也就是每一个线程都会接收到。并通过pthread_sigmask来设置每一个线程的掩码来控制每个线程的信号处理的情况。并且,所有线程都共用同一个信号处理函数,这就很糟糕了。一般来说通过在建立子线程之前开启所有掩码让所有的线程都不收到任何信号,然后再在一个专门的线程中集中处理线程。sigwait返回收到的信号。也就是sigwait和中断式的信号处理二选一。
但linux同样也提供了向特定线程发送信号的函数pthread_kill。
如果没有设置信号掩码,那么信号处理函数也会被新来的信号中断,但如果不用sigaction,那么默认一般都是全掩的,如果掩码了,那么新的信号过来就会暂时被阻塞,挂起到挂起信号集,直到掩码结束,进程就会接收到这个被阻塞的信号。而很显然,掩码维护了一坨子信号,因此对于这个信号集也有专门的信号集函数来处理,也就用来设置掩码。
可以用strace来追踪程序中的信号处理过程。
SIGHUP:一般表示要求重新读配置文件,根据变化更新服务
SIGPIPE:当往关闭的管道里读写的时候就会发生并使程序终止,一般要IGN,或者也可以使用IO复用的函数来处理关闭管道的一些事情
SIGURG:除了监听IO复用的信号来处理带外数据,带外数据来的时候也会触发SIGURG,我们也就可以在这里设置特定的读带外数据的标志进行读了。需要用sockatmark来定位带外数据。
操作超时后会返回特定错误。
一般处理定时任务都是隔一个固定时间调用一下一个处理函数,看看有没有定时任务到期了。而这定时一般用alarm来进行,到时间后就会发出特定的信号,调用处理函数并再次设定下一个alarm。而定时任务要么用有序链表来实现,要么堆。
然后由于不止有IO事件,还有其他事件,因此epoll不应该设置为无限等待。
epollwait的这个超时实际上也可以作为类似的固定时间调用,但由于它是一有信号就返回,因此需要动态的调整超时时间,当有一次epollwait返回时0的时候,那就是超时了,也就是到时间了。
时间轮算法就是对于定时进行散列,比如设置一轮时1s,总共6个分区,那么就是每秒的对应1/6会到对应的分区里,但是这个分区本身仍然是一个有序链表,时间轮每一轮就走到下一个分区就好了,本质上就是hash加有序链表。
要么就是用堆。
fork的时候大部分都很原本的相同,但又一些仍然会不同。并且数据并没有直接复制,而是继续和父进程共用一块,只有在修改的时候才会真正的进行复制。
当子进程运行完而父进程还没运行完的时候(为了让父进程能跟踪子进程状态,子进程在运行完后还会保留),或者父进程先死了,子进程的父进程就变成init了,这种状态就是僵尸进程,没用但是占据着内核资源。
通过wait来等待任意一子进程退出,waitpid就是指定。一般都是在子进程结束的那一瞬间父进程去wait一下最好,而子进程结束的时候会给父进程发一个信号SIGCHLD,这样就可以了。
而父子进程通信一般用管道,一方关一个fd,就单方向了。
信号量
semget(标识符,信号量集大小,flag(低9位控制权限3*wrx))用来获取或创建信号量集。
通过将标识符设置为IPC_PRIVATE可以不管三七二十一创建新的sem。有着不同的semid,而其他如果相同的标识符一定会创建出来相同的semid。
这里的标识符和semget返回的标识符不是同一个标识符,后续操作用的标识符都是semget返回的标识符。但semget注册用的标识符是特用的,虽然都是一一对应的。
semop(标识符,操作数组,数组元素个数)
操作数组:信号量集中的编号,增减大小(如果是0就是等待它为0),flag(nowait不阻塞或者undo就是会记录)
semctl(标识符,信号量集中的编号,命令,参数)
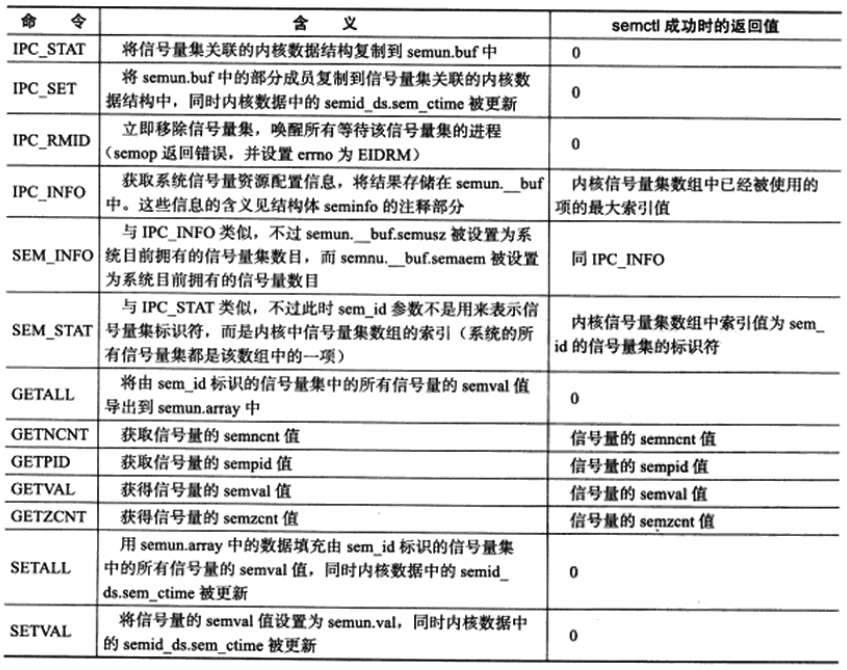
semget出来是没有初始化的,需要用semctl的setval设置最大值。
shmget(标识符,共享内存大小,flag(低9位控制权限3*wrx))用来获取或创建共享内存。
SHMHUGETLB使用大页面分配共享内存,SHMNORESERVE不使用swap。会memset0。
使用shmat/dt来映射共享内存,shmat(标识符,地址,flag)返回地址,可以选择不指定,shmdt(地址)。
shmctl进行控制。
也可以使用POSIX的shm_open和shm_unlink和mmap和ummap来操作,但是要家-lrt。
还有一种是消息队列。相较于管道,它能不fifo,而是能够选择其中某种类型的第一个或者之类的。调用和其他类似。
上面三种信号量,共享内存和消息队列可以在系统中用ipc命令查看。
虽然子进程会仍然保留父进程的fd,但是不能直接使用,需要dup一下,需要获得一个不同的指向同一个文件的fd。而为了让两个不相关的进程持有同一个文件,也可以直接通过ipc进行传输fd,然后dup或者之类的。
可重入函数:线程安全的函数
池的分配一般有两种,一种是统一的由一个最高层的去分配,另一种就是将任务加进队列,然后自己去抢。如果一个请求是有上下文的,那么一般由同一个对象去处理。
系统有自己的最大fd数,有的时候需要通过ulimit或者改配置文件去调大。
sysctl也可以查看一些内核配置,比如/proc/sys/fs/epoll/max user watches限制了用户最大epoll监听个数,因为监听会耗内存。

为了调试子进程,可以在程序启动后attach到子进程上
或者在调试时开启follow-fork-mode,通过在进入gdb后set follow-fork-mode。
调试线程会方便一点,通过info threads获取所有的threads,thread ID来切换。
而有的时候只希望其中一个线程继续的时候其他全暂停的时候可以使用set scheduler-locking off(无效果)/step(只在单步执行的时候这个程序单独运行)/on(这个线程单独运行)
而压测一般就是epoll发起很多个conn。
tcpdump抓网络包,lsof看文件描述符使用情况,有的时候要sudo才能看全部,nc用来发请求,strace看信号情况,netstat看网络信息,vmstat看资源使用情况,ifstat网络流量检测,mpstat多处理器情况监测。