磁盘存储器的管理
总共有三个任务:有效地利用存储空间;提高磁盘IO速度;提高磁盘系统的可靠性
外存的组织方式
-
连续组织方式(连续分配方式)
为每一个文件分配一组邻接的盘块,而有时,直接将逻辑文件中的记录按顺序存储到个物理盘块中,被称为顺序文件结构,物理文件被称为顺序文件。但是各文件之间不一定邻接。
则会导致磁盘空间随着删改增加会被分割成很多个小块,可以使用紧凑,但一次紧凑花费时间较长。
优点:顺序访问容易(只要找到第一个盘号接着往下)且速度快(连续,移动距离最短)。
缺点:需要连续空间,产生内存碎片,紧凑花时间长;必须实现知道文件长度,但有时只能靠估算,因此为了避免不够,就会估大,导致空间浪费;不能灵活增删(可能需要移动);难以管理动态增长文件
-
链接组织方式(离散)
将文件撞到多个离散的盘块中,盘块之间用链接指针连接成一个链表。
优点:消除碎片;增删改都很容易;能动态增长
-
隐式连接
目录项指出链表首尾,每个盘块有一个指针指向下一个盘块。
缺点:只适合顺序访问,不适合随机访问(需要一个一个过去);可靠性低,一个指针错误就全烂;
改良:不是一个盘块一个盘块分配,而是将几个盘块形成一个簇进行分配,减少指针存储空间,提高速度,但增大了碎片。
-
显式链接
将整个链表的所有指针都存放在内存中的一张文件分配表FAT(File Allocation Table)中,首地址放在FCB的物理地址中,由于是在内存中,所以效率更高。
-
-
FAT技术
引入卷的概念,将一个物理磁盘分为4个逻辑磁盘,被一个就是一个卷(分区),每卷都划分一个区域存放自己的目录和FAT表及字母。现代已经不再只能划分4个了,已经可以随意划分了。
-
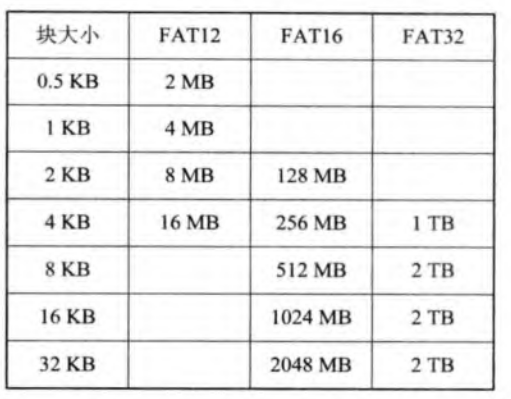
FAT12
一般为了安全性,会配备两张完全一致的FAT。
一个盘块的大小为512B,而2^12=4096,因此每卷最大为2MB,整个磁盘最大为8MB,显然不够。
-
簇
因此引入簇,将几个盘块作为一个虚拟扇区。分配时按照虚拟扇区分配,而非盘块。
簇不但能扩大容量,还能减小FAT的大小,减少访问FAT的存储开销,但也会造成更大的碎片。并且也没有引出容量的质变,且只支持短文件名。
-
FAT16
增加到16位,2^16=65536,而簇可以是4、8、…、64,因此最大为2GB。但这种情况下,每个簇大小为128KB,会浪费10%-20%的空间。
-
FAT32
为FAT的最后一个版本。增加位数至32位,并允许采用更小的簇,并根据分区大小动态调整簇的大小。提高了利用率,但FAT的增大,导致运行速度更慢;同时有最小分区大小;单个文件的长度也有要求;且不能向下兼容。
-
-
NTFS(New Technology File System)
- 新特征:使用64位;可以很好支持长文件名;具有系统容错功能;能保证系统数据一致性
- 磁盘结构:基本没什么变化,除了簇被称为“卷因子”,并且簇的大小仍然是根据卷的大小定的。而对于簇的定位,使用逻辑簇号LCN(按顺序对簇标号,最后将序号*簇长度即可)和虚拟簇号(一个文件类的相对簇号,只需知道首地址就很好定位)。
- 文件的组织:将一个卷中的所有文件信息、目录信息和可用未分配信息记录在主控文件表MFT(Master File Table)上,每个文件占一行1KB,记录文件的所有属性,如果存不下,就在其他地方找空间存,并用一个指针指向它。并且,由于文件并不是所有的簇都分开放,很多的情况下都是连续的,因此不需要记这么多指针,减少存储。
- 缺点:兼容性不好
-
索引组织方式
-
单级索引组织方式
FAT主要有两个问题:FAT很大,调入内存会占很多空间;读大文件要跟着链表找啊找,很慢。
但实际上,读取一个文件并不需要整个卷的FAT,只需要这个文件相关的所有盘号。因此为每一个文件分配一个索引块,
记录所有分配给该文件的盘块号,而文件的目录项只需要有一个指向这个索引块的指针即可。
这样就支持直接随机访问了,而不需要一个一个找。在大文件上优于链接组织方式。但是对小文件没有几个盘块号索引块的利用率就很低下了。
-
多级索引组织方式
对于某些非常大的文件,一个索引块可能存不下,因此可以采用多级索引,用一个索引块,记录次一级的所有索引块。
这样查找的效率更高,并且允许的最大文件也更大了。
但是访问一个盘块时,启动磁盘的次数也更多了,对于在文件中占多数的中小文件也是如此,效率也就变慢了。
-
增量式索引组织方式
因此在实际情况中应该分类讨论,小文件的地址直接存在FCB中,中文件用一级索引,大文件用多级索引。
例如Unix System V中,就设置了13个地址项。前10个是直接地址,即直接盘块号,用于小文件。第11个提供一个间接地址。第12个提供一个二级间接地址。第13个提供一个三级间接地址。根据情况来设置后面几项。
-
文件存储空间的管理
前面只是探讨了组织方式,却没有研究该如何找出哪一部分没有被分配,以及应该分配在哪。
-
空闲表法
-
空闲表
属于连续分配方式,有一张空闲表来记录,分为三列,序号,第一空闲盘块号和空闲盘块数,并按照起始盘块号递增排序。
-
存储空闲的分配与回收
采用首次适应算法和最佳适应算法。并且在回收的时候也要考虑合并。
虽然内存分配上连续分配很少采用,但是外存中因为连续分配速率较高,因此仍然在使用中。对于文件系统,小的文件用连续,大的用离散。
-
-
空闲链表法
-
空闲盘块链
将磁盘上所有的空闲空间以盘块为单位拉成一条链。每次创建就从链首取下足够多的盘块,回收时直接放到链尾。实现简单,但由于以盘块为单位,因此效率低。
-
空闲盘区链
将磁盘上所有的空闲盘区拉成一条链(需要记录指针和长度)。可能是一开始就是一块大的盘区。一般采用首次适应算法进行分配,如果没有也可以分配不同盘区内的区块,可以通过显式链接的方式提高检索速度,回收时要考虑合并。过程复杂,但由于链短,每次为文件分配多个连续的块,因此效率较高。
-
-
位示图法
位示图可描述为一个二维数组,按顺序与每一个盘块对应,1为已分配,0为未分配。
从位示图上找到n个0,然后根据i,j计算盘块号,然后标记为1。
回收时反转换,并标记为0。
优点:体积小,可以在一开始就保存于内存中,省去了很多磁盘启动,并且容易查找连续空闲区间
-
成组链接法
当用于大型系统的时候,空闲表和空闲链表都会太长,不适合,而成组链接法就能解决这个问题。
将空闲盘块分为若干个组。每一组都要存放后面一组的指针和这一组剩余的空闲盘块数。
一开始空闲盘块号栈中存放着第一组的所有数据。每次从栈顶开始分配盘块。当用尽后,也就是N=0时,就将后面一块数据复制到栈中继续分配。回收时就计数+1,并放回到空闲盘块号栈中,当满100后就移出栈,从0再造一个栈。
提高磁盘IO速度的途径
为了提高对文件的访问速度,有三个因素:目录的结构导致的查找时间,文件的结构导致的访问时间和磁盘的速度。
-
磁盘高速缓存(Disk Cache)
就是在内存中为磁盘盘块设置一个缓冲区(其中保存一部分盘块的副本),每次先去缓冲区看眼,如果有,就不用再磁盘IO了,否则再磁盘IO。
-
数据交付方式(该如何将缓冲区中的数据交给程序)
一种是直接拷贝过去,另一种是将指向高速缓存中要求数据的指针交给程序(更快)。
-
置换算法
虽然类似内存置换的三大算法LRU,NRU和LFU,但是情况还有些不同,还需要考虑访问频率(比快表频率低);可预见性(哪些更会在将来被访问);数据一致性(内存是易失的,但其中的数据可能已经更改了,就和外存不一样了)
所以将高速缓存中的所有盘块拉成一条LRU链,影响数据一致性的盘块和不会再使用的盘夸靠前,其他靠后。
-
周期性地写回磁盘
有些盘块可能永远留在高速缓存中,造成数据一致性问题。因此每隔一段时间(UNIX:30s)强制全部写回。
-
-
提高磁盘IO速度的其他方法
- 提前读: 如果在顺序访问,那后面一块在下一次必然会读进,那不如这次直接先把下一次读的读进高速缓存
- 延迟写:原本在更改后应该立即写回磁盘,但也不急,不如直接挂在空闲缓冲区的末尾,等到被使用的时候就会自动写回了,而且在这段时间使用也不用再IO
- 优化物理块的分布:虽然磁盘上盘块是离散的,但是其之间的距离也会影响IO速度。在分配的时候用位示图就很容易找到接近的盘块,提高速度,而空闲表就不行。因此有一种方式是按簇来分配,这样一簇中的至少是邻近的,比较快。
- 虚拟盘:可以将内存中的一部分当作磁盘。与高速缓存的区别在于虚拟盘是用户控制的,而高速缓存是OS控制的。由于他是易失的,所以一般只放一些临时文件,但对用户来说是透明的。
-
廉价磁盘冗余阵列(RAID)
利用一台磁盘阵列控制器来统一管理和控制一组磁盘驱动器。
-
并行交叉存取
将每一个盘块切分为很多n子盘块,分别放在n个磁盘上,这样传输的时候就可以并行传输了,速度提高了n倍。
-
RAID分级
0级:能够实现高速IO,但无冗余校验
1级:具有磁盘镜像,一半作为数据盘,一半作为镜像盘,利用率只有50%,但很可靠
3级:只利用一台奇偶校验盘来完成数据校验,其他都作为数据盘,利用率高
5级:有独立传送功能,每个磁盘都可以独立的读写,校验的信息也分布式放在各个磁盘上
6级:设置了一个专用的可快速访问的异步校验盘,有更好的性能。
7级:所有磁盘都有高的传输速率和优异的性能
-
优点:可靠性高,IO快,性价比高
-
提高磁盘可靠性的计数
可以防止系统因素和自然因素造成的不安全性。
容错技术通过设置冗余部分来提高可靠性。
-
第一级容错技术SFT-I
主要用于因磁盘表面缺陷所造成的数据缺失。
-
双份目录和双份文件分配表
文件目录和文件分配表非常重要,因此备份一次,当损坏时,也可以用备份的继续访问。
-
热修复重定向和写后读校验
如果磁盘只有很小一部分坏了,那么仍然是可以补救的。将2%-3%的磁盘作为热修复重定向区。在写入时为了保证写的正确,就应该再将其读出到另一个内存缓冲区,并与在缓冲区中写完但还没删掉的数据进行比对,如果不一样,则说明这一部分有缺陷,就将热修复重定向区暂时替代这一部分有缺陷的居于。
-
-
第二级容错计数SFT-II
主要用于防止磁盘驱动器和控制器故障所导致的系统不能正常工作。
-
磁盘镜像
增加一个完全相同的磁盘,每次向磁盘写入的时候,也要将数据写到备份磁盘上。
-
磁盘双工
前者是将两个磁盘连接到同一个磁盘控制器上,但是如果磁盘控制器出现问题,就出事了。因此,增加一个磁盘控制器,将两个磁盘分别与一个磁盘控制器相连接。而这种情况下可以进行并行读取,因为两者都有独立的通道,而前者只有一个通道,不能并行。
-
-
基于集群技术的容错功能
集群系统能提高并行处理能力和可用性。
-
双机热备份模式
一台主服务器,一台备份服务器。平时只有主服务器服务,如果一旦主服务器出现故障,备份服务器就会监视到并直接替代,修复后主服务器再替代回来。
而为了实现这一点,就通过一条镜像服务器链路MSL连接起来(通信线路最好也有备份),二者完全独立,支持远程热备份,但效率只有50%。
-
双机互为备份模式
两个互相运行不同服务的服务器,通过网线连接,并最好有路由器再连一根备份线路。每个服务器有两个硬盘,实时存储对方的数据,但一般情况下这个镜像盘是不能被本地用户访问的。直到对方出现问题,就立即在本地启动这个服务,直接接管。除了速度稍微慢了点,但问题都不大。
-
公用磁盘模式
上述两种都要传输数据。因此可以让很多个机器连接到公共的磁盘系统上,每个机器使用其中一个卷。当有机器发生故障,直接让另一台机器使用这卷,接管服务。
-
-
后备系统
由于磁盘系统不够大,因此一般把暂时不需要但仍然有用的数据放在后备系统中保存起来,用于防止系统故障导致数据丢失。
一般用磁带机(只适合顺序且慢,但容量大),硬盘(移动硬盘速度高且方便,固定硬盘驱动器,有两个大硬盘,每个分两个区,其中一个存自己,一个存对方的数据)和光盘驱动器(只读光盘驱动器不能用,因为不能写,所以只能用可读写光盘驱动器)作为后备系统。
数据一致性控制
一个数据可能放在多个文件中存储,需要保证这一数据在不同文件中的一致性。
-
事务
-
事务的定义
用于访问和修改各种数据项的一个程序单位。被访问的多个数据可以在同一文件中,也可以在不同文件中。只有所有数据都修改完成了,才提交操作,如果发现其中有一个失败了,就要进行回滚,将所有的已更改的改回来。让事务操作具有原子性。
事务需要具有四大属性ACID:原子性(Atomic),一致性(Consistent),隔离型(Isolated)(其他程序不能看到中间状态),持久性(Durable)(即永久性)。
-
事务记录
事务的核心实现是事务记录(被放在一个可靠的存储器中)。其中存储事务名,数据项名,旧值和新值。而在每次进行操作之前,无论修改还是提交,都需要先写记录。
-
恢复算法
因为有所有的操作,因此可以对这些操作进行redo或者undo。当发生故障的时候,可以通过时候有对应的提交操作来决定这个操作到底是要redo还是undo。(需要全部重做一遍,因为对文件的操作是在内存中进行的,是易失的)
-
-
检查点
-
检查点的作用
由于有各种乱七八糟的事务,因此会有很多很多记录,而每次恢复都要全部做一遍。而通过放一个检查点,就将记录全放进稳定存储器中,接着是已修改数据,最后是检查点放进去。
-
恢复算法
后续恢复的时候就不需要重新全部做一遍记录了,只需要对于最后一个检查点后面的做就可以了。
-
-
并发控制
现在很多情况下都是多个用户在同时执行事务,但事务对数据项的修改是互斥的。因此需要通过互斥锁(允许一个对象读写)和共享锁(允许也只允许多个对象同时读)。
-
重复数据的数据一致性
有时为了保证可靠性,对于一个文件有好几个备份,因此就必须对这几个文件保证一致性,不然备份了个屁股。
-
重复文件的一致性
原本一个文件名对应一个索引节点,现在的目录中一个文件名对应很多个索引节点(即重复文件)。当一个文件拷贝被修改时,要么根据其文件目录找到另外几个索引节点并做同样的修改,要么为修改完的文件直接建立几个拷贝对原本的拷贝进行替换。
-
链接数一致性检查
共享文件的索引节点中存放着counter记录引用数,而这一数字需要和真实链接的数量一致。如果少了,就可能最后会有几个指向了一个已经被”析构”的索引节点,并后来又指向其他索引节点。如果多了,就会导致这个索引节点指向的永远不会被”释放”。因此需要通过扫描整个文件目录进行统计来保证这个数字的正确。
-