mit_os
lesson1
exec的时候虽然会把进程映像替换,但是会保留FD,并且会保留FD中的偏移量。
但即便保留了FD,也可以在exec的时候更改FD,进行重定向,并且不会影响主进程。
open是可以open文件夹的,并且也可以读出来的就是这个目录下的所有文件名,需要按照一定格式去一个一个读出来。
exit是用来结束进程的,一般子进程结束后就要exit一下,虽然不exit也问题不大,感觉类似return 0把。
fork的子进程是从fork这一行继续执行,而exec则是从头。
第一个参数是程序名字,所以exec的第一个参数一般没什么用吧。
只要我不exit,那么我就能一直去exec其他进程,直到我exit,就会立即结束,源程序也就会开始运行。
虽然看似创建并替换好像比较浪费,但实际上会用虚存技术来把这个浪费优化掉。
sbrk,申请更多内存。
FD1是标准输出,FD2是错误输出。
对于read和write文件都有一个偏移量,读写都是从偏移量开始的。
虽然cat的时候是从0读入,1输出。但是在exec的时候是保留FD的,因此并不知道exec之前原进程是否重定向过输入输出。
close可以关闭FD。使用的FD永远是当前进程未被使用的最小自然数。
因此一般的过程都是,先fork,然后在if里重定向,然后exec。
而为了更改FD对应的文件,就需要先close掉FD,然后再open。
TRUNC是把文件中的所有内容删了。
使用dup可以给同一个低层文件创建一个新的FD,这两个FD共享同一个文件,同一个偏移量。但如果是另一个open或者不是在同一个进程中,那么就不会共享偏移量。并且dup只有一个参数,即文件标识符,然后这个新的文件标识符也是当前进程未被使用的最小自然数。
ls existing-file non-existing-file > tmp1 2>&1。未写任何东西的>是指将1进行从形象,然后再将2重定向到1。这里的&代表将这个1是一个文件标识符(作为目标的时候需要&)。
对于一个管道来说,0是读,1是写,而当且仅当所有写的FD都close之后,read才会返回0,表示结束。而其会返回0的原因是管道的末尾被写入了EOF。
Pipe的代码。
1 | |
需要注意的是,虽然在子进程中关掉了管道,主进程中也要关掉管道。
管道也可以通过临时文件重定向来解决,但是他有三个好处,不用自己清理临时文件;不占用太多存储空间;两条命令可以并行执行。
对于一般的文件读写,都是在用户空间完成的,而如果是设备文件,读写则会直接调入内核空间。
Unix就是索引节点文件结构。索引节点中会有一个属性表示这是文件夹,设备还是文件。
如果在open一个文件并给他创建FD后,然后消除他的所有链接,那么他将变成一个没有名称的临时inode。
对于所有的命令来说,实际上都是存在一个对应的程序,而shell只是运行了这些程序。而只有cd是例外,sh内置了这条命令,因为切换文件夹最终切换的是子进程的文件夹。
Task 1
它的调用很奇怪,只需要声明,就对应到对应的系统调用了
管道一般是单向的,虽然有的时候如果用的好可以用来做双向,但是双向一半就直接用两个管道算了
[Bell Labs and CSP Threads](https://lhish.github.io/hide/Bell Labs and CSP Threads)
实现筛素数。
草你妈。这勾八的fd在fork的时候完全复制是真nm逆天。
lesson 2
实际上,C程序在内存上除了程序区,栈区和堆区,还有data区,用来存放全局变量。
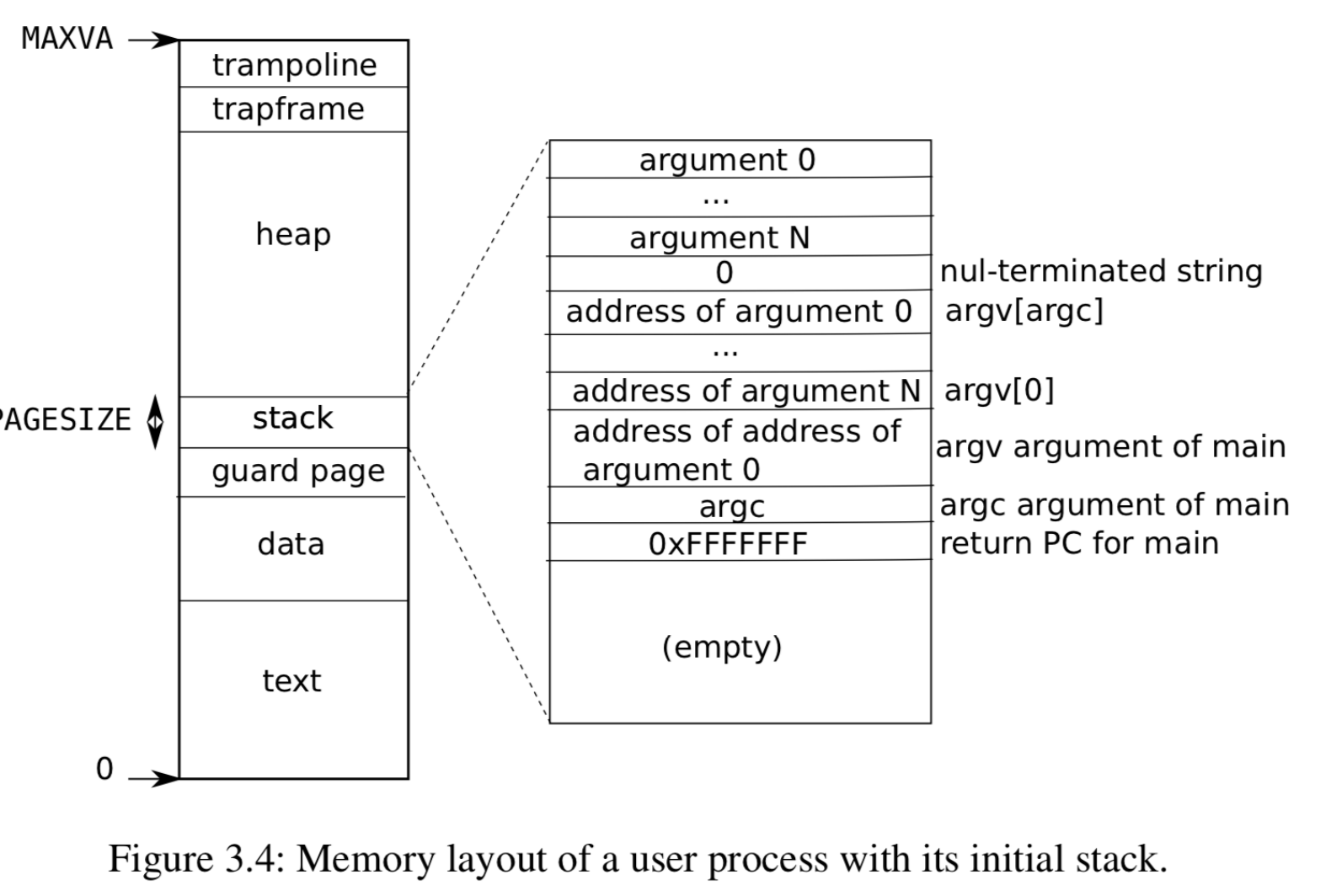
对于整个程序来说argc和argv就像是调用main的人的本地变量一样。这里实际上是每一个程序的内存空间。trampoline用于保存系统调用的语句,trapframe则是用于保存PCB的状态。
lesson 3
用户态使用系统调用的时候不应该通过地址来访问,因为这样就可能跳过内核态对于这个系统调用请求的验证部分,导致非法的事情。
使用微内核的还有一个好处就是内核内的代码很少,也就更少的概率出现更加严重的内核错误。
为了帮助实施隔离,进程抽象为程序提供了它拥有自己的私有机器的错觉。进程为程
序提供了看似私有的内存系统,或者 address space ,其他进程无法读取或写入。进程还为
程序提供看似其自己的 CPU 来执行程序的指令。
机器模式:kernel
用户模式:user
管理模式:操作系统一般处在的状态,管理应用程序,并响应系统调用
当刚刚开机的时候,首先先用汇编分配一块物理内存供每个cpu分别使用,然后在机器模式的情况下设置监管模式的一些设置,如中断,进程号,与接下来要执行的函数入口,然后正式通过一些技巧回到监管模式(start是机器模式下的init)。完成后调用main函数(监管模式下的init),在监管模式下设定一些初始的东西,如页表等。然后就准备启动用户模式的第一个初始化程序:主要就是准备页表并准备pcb,而其进程映像是由汇编转为二进制后再直接将这个二进制写进内存做到的(就是exec init)。当实际上这里并没有直接执行init,因为现在还在监管模式,cpu都还没有调度呢。等到时候调度的时候,这个runnable的程序才真正的会被调度。而这个时候就会初始化shell。
关于syscall。实际上是有一个汇编的Usys.S(对应的声明在user.h中),其中将系统调用和对应的数字绑定,存储在对应的寄存其中。而在kernel中,也用一个数组将数字与对应的系统调用绑定。这样,当调用syscall的时候,就会自动根据寄存器中存的数字调用对应的系统调用了。
lesson4
虚拟地址可以实现隔离性。对于每一个程序而言,他交给cpu的都是虚拟地址,而通过mmu查找对应的页表之后才是真正的物理地址,为了实现隔离性,每一个程序的地址都是从0开始的。而存储页表的寄存器是satp(risc-v)。每次进程切换的时候就要改一下,并且切换的时候很显然要清空tlb,因为现在的tlb全是其他进程的。
另外,如果直接用一张页表全部存储,那内存直接爆炸,因此一般是多级的。
pte:page table entry实际上指的就是指向页面的头部的指针
ppn:physic page number
但是存储pte的时候,很显然,是将地址完全存储的,很显然,低位是0。这一部分就可以用于放标志位,也就是控制这块page权限。
很显然,这里pte指向的值是pa(physics address),否则就无限循环了。
当上述的这些查找页表的功能基本都是通过硬件完成的。
对于一个地址到底是io设备还是内存地址,是完全由硬件也就是主板来决定。
一般不同的stack的虚拟地址也不是连续的,会由一个guard来分隔,避免出现越界。
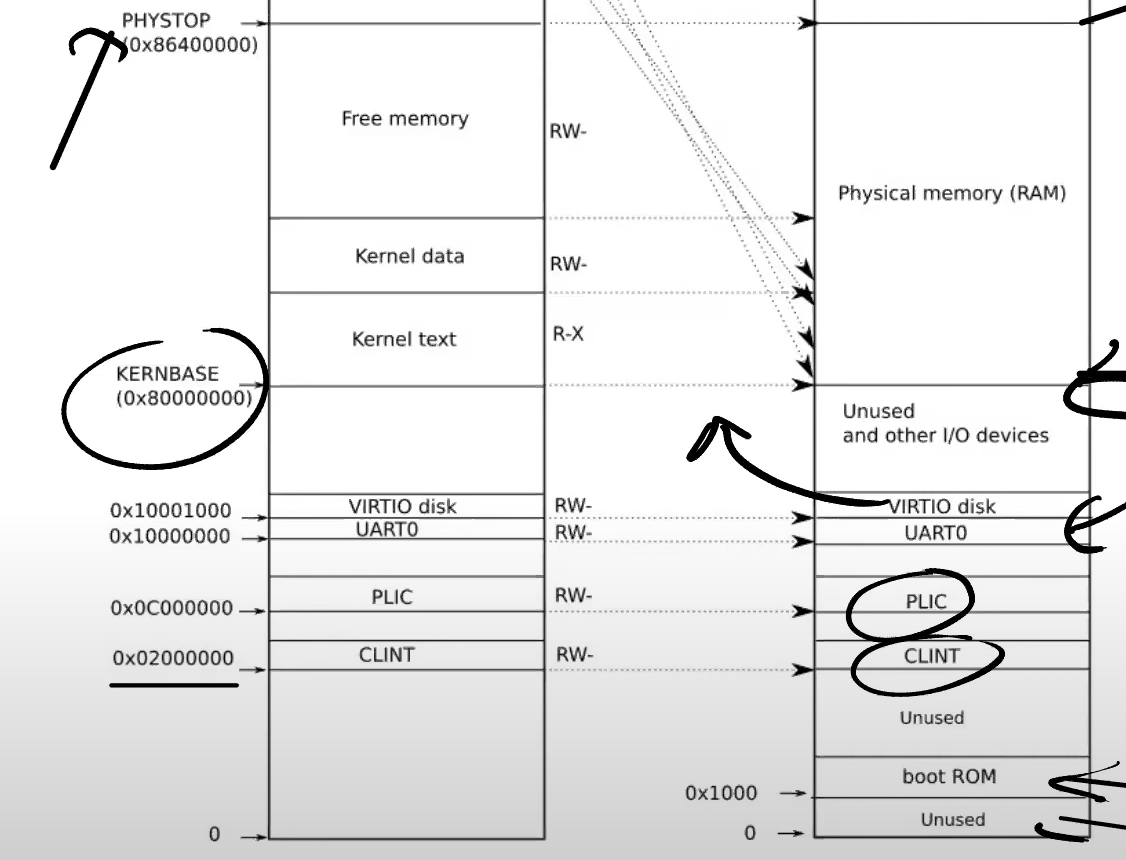
每一个进程都会由一个对应的内核信息部分,而对于他们的用户信息,就放在Freememory中。
一旦执行设置satp的语句,那么在这句语句后所有的地址的含义就全变了。但是对于pc来说他还在增加,所以很难搞。
在这里satp比较简单的原因是xv6的物理和虚拟的地址是一样的。
lesson 5
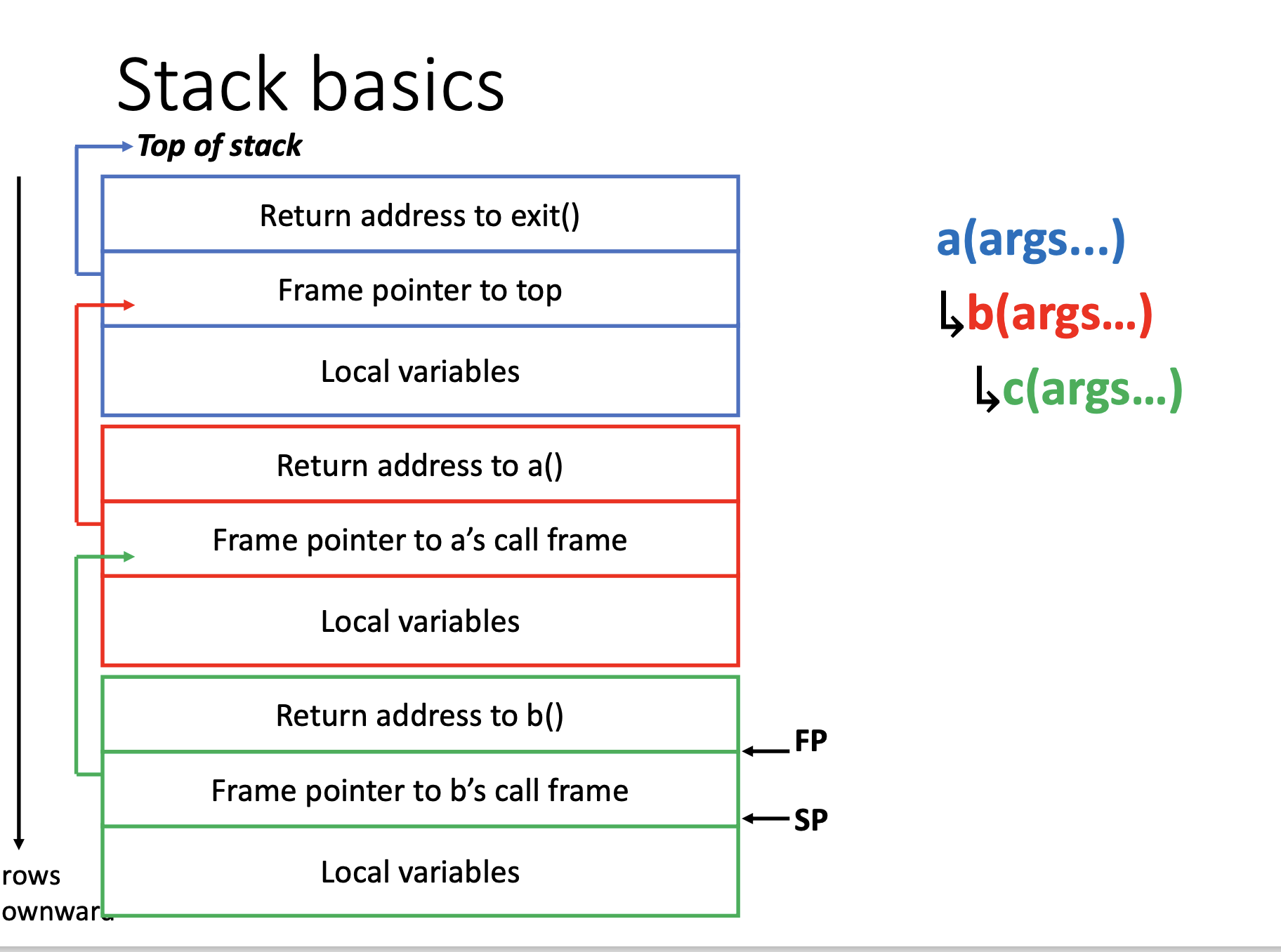
栈中会保存当前的的函数返回位置(前一个函数的位置),前一个栈指针,函数参数,和局部变量。
前两个的相对位置是固定的,因此找起来非常容易。
function pointer寄存器决定了我们当前在哪个函数。
而在汇编中,如果要在函数中call另一个函数,就要手动创建其对应的栈空间,方法就是将sp,也就是stackpointer,指向stack最底下的指针减一定大小,也就做到了扩充栈空间。然后在调用前要存储当前函数的返回位置,然后调用结束后再取回来。
在调用函数的时候,有的寄存器会随之更改,比如返回位置,而有的寄存器不会随之更改。
lesson 6
寄存器:PC,SP,FP,mode标志位(表示当前是用户还是监管模式),SATP(pagetableaddress), STVEC(内存中处理trap的起始位置),SPEC(trap过程中保存PC的值),SSRATCH(交换用的temp,在trap前一直存放的是trapframe的地址)。
trap过程:保存所有寄存器,保存PC,更改mode,SATP指向kernel页表,更改堆栈指针指向的位置
相较于用户模式:监管模式能够访问用户模式不能访问的内存,并且能够更改各种原本不可更改的寄存器,但访问时仍然是根据页表,而非直接物理地址来访问。
首先保存系统调用数字到寄存器。
此时所有的a0-a15就是调用的参数。
然后ecall,实际上是调用存储在用户内存空间最顶端的trampoline函数。
在这个时间点,不能使用任何的寄存器,因为会把用户空间时的寄存器的值覆盖。
而为了做到这一点,就应该要进行交换,而非赋值。通过sscratch可以将两个寄存器互换。
ecall是不会立即切换页表的,因此trap的启动部分必须在用户空间。
ecall(cpu命令)实际只做了三件事,更改模式,保存pc,这样在这里也就能继续用pc了,将STVEC中的值放进PC中。
ecall只做很少的事情保证其的灵活性。
为了能够保存寄存器,可以将其放在trapframe中预留的32个槽位中。并且,其中也有内核先放进去的内核页表等数据。
为了从监管模式返回用户模式,必须要通过sret,而这个函数就会设定各种初始值。
然后将各种内核事先放的值取出来:kernel table page,kernel stack pointer,tp(当前运行cpuid),usertrap函数(下一个要运行的函数)地址
在切换的satp的时候要清除缓存,需要加barriar。
放satp。
在切换的时候,程序不会崩溃,因为这段程序在两个内存空间中的映射是相同的。
然后进入usertrap
设置stvec,获取进程存储pc,不能存储在spec中,因为可能会有递归调用导致覆盖。获取trap原因,调整pc往后一句语句以免重复执行。打开中断,进行系统调用。接着避免恢复一个被杀掉的程序,如果是时间片结束那就放弃cpu。
然后是usertrapret,首先暂时关中断,在sret的时候再打开(因为可能会发生错误),设置stvec,存储4大内核参数,调整一些状态位,然后写回sstatus,设置spec,获取要调用函数的地址,然后调用。
然后又是汇编,更改satp,更改页表,拿出寄存器,然后sret:开中断,拷贝PC,切换模式。
实际情况中会用更加高效的方式实现trap。
函数的栈和函数的位置指针是不同的东西,ra是指向前一个函数的位置,而fp指向的是前一个函数的栈。
lesson8
page fault可以让页面的映射变得动态。
显然page fault是个trap,我们会获取到地址,原因(缺页可能有多种原因)和PC。
很常见的一种情况是程序员由于不清楚要程序要使用多少内存,而申请过多内存当不进行使用。因此对于程序申请内存,例如调用sbrk,就可以只是增长大小,当不实际申请空间,当发生page fault的时候再申请。而在释放的时候也要特殊处理一下。
而程序除了text区和data区之外还会有一个BSS区,用于放未被初始化的全局变量,需要一开始被赋值为全0。有一种取巧的方式是,将BSS区的所有页都映射到同一个全0的页面上,这样就减少了很多赋值工作。但是,同样,在page fault的时候,就需要分配一个新的页面,并全部赋值为0。
虽然这均匀分配了代价,但是page fault的代价比普通读写的代价要高。
当想要fork的时候,我们会直接将其空间全部拷贝。然而,实际上,有的时候我们完全不需要对这些页面进行更改,因此,不如fork的时候直接让父子共享同一个物理内存,并将其PTE设置为只读,当发生pagefault的时候,再复制一个新页并拷贝,然后都设置为写。而为了区分这种情况和普通的情况,就需要增加一个额外的变量标记。而此时,释放也就像共享指针一样要根据引用计数计算了。
实际上,连最开始的内存分配都可以不需要,只需要分配所有的页表,然后相应项设置为not_valid,page fault的时候再调页就好了。
有的时候我们需要更快的访问文件,显然内存快于硬盘,因此直接将其全部map到内存上,然后操作完后再写回去。如果多个程序在同时操作,就可能发生问题,因为映射到的都是不同的内存上。
lesson9
为了提高内存的使用率,不但会有基础的使用,还会使用很多的buff,加快速度。
实际上设备中断和缺页中断差不多。只不过有三点不同,设备中断的编程由于设备手册不一导致的困难,生成的中断于当前cpu无关,生成中断和cpu运行是并行的。
设备被映射到内存空间中,同时也会连接到cpu上,通过一个PLIC中转这些中断。由他来决定每一个中断应该由哪一个cpu处理,如果所有cpu都在忙,他就像当于缓冲区。
一个驱动一般分为两个部分,bottom部分和top部分,bottom处理中断,并将数据写入类似队列的东西,top部分就是用户程序的接口,像当于从队列中读数据。
虽然读写用的也是load和store的接口,当行为却不一定是,可能是发送数据等等。
整体初始化流程:将中断管理交给管理模式,初始化所有设备,初始化的时候要关中断,这样设备就能发出中断,初始化plic,设置接收哪些设备的中断,然后设置cpu接收的中断的类型,这样plic就能正常分发了,最后让cpu打开中断,能够接收这些中断。
top实际上调用write的时候,调用sys_write,会由于其是一个设备,而去调用对应的函数。
bottom:收到中断后就会关中断,然后存储cpu信息,每一个cpu如果在摸鱼,就获取中断情况,如果自己要处理,就跟plic说自己要处理,uart就根据自己的buffer进行输出。
当加入了并行:在对同一个设备操作的时候要加锁,需要原子性的地方,就需要关中断。
对于消费者和生产者,如果空了或者满了都会开始睡觉。
lesson10
多核cpu的原因:时钟频率和单核性能上不去了
为了提升性能,要增加cpu核心,使用并行,当为了保证并行正确性,又要使用锁来使他串行。
race condition是概率性发生。
更加细节的锁能够更加并发。锁必须我们自己加,如果对每一个对象都加一个锁的话,实际上还是有问题的,应该是对一个操作整体加锁。但是这很难判断,如果进行自动加锁的话,那么又会演变成大锁了。
xv6是通过按序获取的方式来防止死锁的。
设计多线程的方法:从大锁开始,如果不能使用多线程,就拆分锁。
锁的实现方式一般都是通过内核的一条指令,这条指令由硬件保证原子性,做到,对地址加锁,然后将数据读出,再将新数据写入。需要注意的是,锁的时候要关中断,这是为了避免在锁的时候陷入中断然后重复获取锁导致锁。并且,为了保证不因为编译器优化而导致的指令顺序变化,就需要加一些barriar。
lesson11
线程包括PC,寄存器和stack。一种是有几个cpu就跑几个线程,另一个是不停切换cpu。
内核线程会共享内存,但用户级线程不会。
为了实现切换,就必须要有调度器,就像协程也会有一个调度器。为了保证不会有计算密集型线程一直占用cpu,几乎所有cpu都实现了计时器中断。使得即便是不愿意切换的线程也能被切换。
线程三大状态。
对于要保存的内容,一个线程总共有两个部分,首先是所有线程共有的内核线程的context,然后是用户线程独有的trapframe。对于普通线程来说,context保存在线程中,而对于调度器线程,由于其是每个cpu一个并且没有proc信息,因此保存在cpu信息中。
当要切换的时候,首先要切换到调度器线程,调度器线程也是一个独立的内核线程,然后再由这个调度器线程在切换为要调度的线程。
内核程序虽然都一样,当可以通过当前运行所在cpu在运行的用户线程来知道自己属于谁。
在switch的时候要保存寄存器,当并不是全部保存,因为有一部分已经被保存完了。
有些地方要使用汇编的原因是要与寄存器交互,而这要么通过汇编实现要么通过内嵌汇编来实现,那不如直接写汇编程序。
通过swtch(p,myproc→context),就将当前运行的挂起了,然后将调度器线程,也就是存储在myproc中的线程进行调度。而调度器线程其实就是main.c,在跑scheduler函数。他首先将中断给打开,因为最快的永远是要中断的,然后找到一个可以运行的proc,调度,如果找了一遍没有东西调度就摸鱼等中断。
只有第一个被创建的进程和fork出来的进程不是被切换过来的,因此在其被第一次调度的时候,就伪装是从这样的内核线程切换到调度线程的,然后也就能通过这个伪造的函数走到真正的用户线程。
lesson13
调度器需要加锁的原因是每个cpu都有一个调度器在跑。
在进程调度的时候也不允许持有除了该进程锁以外的其他锁,否则会形成死锁。并且这也不能通过定时器中断来解决,因为在acquire的时候会通过关中断的方式来避免死锁。
除了计时器中断,还有很多其他中断,这些中断都是要等待一些其他事件的完成,一种方式是直接循环知道为真,但只适合非常接近的事情,否则耗费资源太多,因此,一般都会有一个sleep,将这个线程加到这个sleep_channel上去,开始摸鱼,然后直到事件完成主动触发wakeup这个channel,这个上面的所有线程都会变成runnable。
这个sleep的时候同时还要传入一个锁。因为,很显然,这个进程都要切换了,那么他就不应该继续持有这个锁,然而,如果在外面进行释放,可能会有别的cpu在这个进程的状态被设置为sleeping前就因为中断而触发了wakeup,导致了这个wakeup的lost,因此,sleep需要被特别的设计一下。在wakeup的时候,对于其中的每一个进程的判断都会加锁,那我只要保证在我释放锁的时候到我重新拿到锁的这段时间内这里都会阻塞即可。那么,我只需要在释放这个锁之前,先取得进程锁即可(反正调度的时候要将这个进程锁掉(在调度器中改完相关的状态就会被释放了,直到再次被调度的时候再被加锁)),最后反向释放即可,这样就保证了,针对于这个线程的wakeup是在释放这个锁的时间之外被判断的。
并且,被唤醒了,不代表当前就一定是条件满足的状态,因为可能同时有多个被唤醒,而其他被唤醒的可能抢先一步,导致条件又不成立了,因此即便被唤醒了也仍然要判断一遍条件。
这个在现在已经变成了惯用法了。
即一开始加锁,然后要睡了就在里面通过解锁,然后出来的时候仍然是上锁状态,即sleep不影响上锁状态。最后再释放锁。而为了保证两段前所说的,所以sleep外要加上一层循环进行判断。
而对于结束进程,需要进行慎重考虑,因为进程可能持有资源,或者在干某些非常重要不能被打断的事情。在exit的时候,释放文件,目录,然后接下来很重要的一步是将自己所有的子进程交给init进程。而为了能够让init接收,就需要首先让init wakeup,然后获取进程的父进程,因为父进程可能在wait子进程,所以要先wakeup他,然后更改孩子的父亲,调整进程状态为zombie状态,这种状态下进程不会被释放,但是也不会被调度,其还没释放的资源也就不会被别人拿去使用。然后进入调度。
接着剩下的资源就交给这个被释放进程的父进程来解决,因为有一些资源进程自己来释放很困难。解决的方式就是父进程会wait这个子进程结束,然后就会释放掉他的资源。而如果一个进程有子进程,而这个进程要被杀掉,那么就没有对应的父进程来wait他们了,因此让init成为父进程,而init里面就是疯狂wait。
而在wait中就是等待遍历寻找一个zombie子进程。如果没有找到,就先睡一会。由子进程来唤醒。然后就释放table,释放proc。就结束了。这其中也要注意wakeup lost。
kill可以直接杀死另一个进程。当实际上他什么都不做,他只是将这个进程找到并唤醒,设置为running然后将其killed标志位设置为1。而在系统调用的时候,进程会自己检查iskilled是否被设置。如果被设置就会自己exit。当这只是在用户空间运行的情况。
当如果已经在内核运行了,即便在睡觉也会由于设置为了running而能够离开sleep。而在内核中的很多地方都会进行这种iskilled检查,并立即返回,然后exit掉。
虽然停止进程比较简单,但是关机就比较复杂了。
lesson 14
文件系统一个很重要的点就是即便发生了fatal error,他们仍然保持完好。
另一点很重要的是,由于load和store很慢,因此要尽量避免或者通过并行来提高性能。
文件会记录文件大小,可以指向同一个文件,等等各种特性。
为了实现这些特性,实际上通过的是inode,是代表一个文件的对象,通过编号来区分。
文件系统一般会分成多层,从磁盘,buffer cache,logging,inode cache,inode,文件名和文件描述符操作。
SSD的速度大约是0.1-1,HDD大约是10.
sector:磁盘驱动可以读写的最小单元。
block:操作系统视角下的操作的最小单元。
在磁盘上,除了存储实际的信息,还会存储一些元数据,比如xv6中就存储了super block(描述了文件系统),log,inode,bitmap block(用于记录block是否空闲)。
inode中会存储type,nlink,size,block对应前几个block num,indirect block number,对应一个页表。
可以通过类似二级页表的东西来存储。而文件夹也就是存储了其中每个文件或文件夹的inode编号和名字。查找一个绝对路径的时候,因为root的inode编号是固定的,因此只需要按位置偏移即可。
创建一个文件:标记inode使用,写入空白inode基础文件,更新目录entry,更新目录文件大小,更新空白inode大小。
写文件:更新bitmap,写入,更新大小(和direct block number)。
在一些比较底层的地方,比如buffer cache,就会通过锁来限制。比如限制查找cache的人数;限制对cache更改必须是串行的。
sleeplock能够在开中断的情况下上锁并且不会使用忙等,而是睡觉。也因此,他能够接受中断,因为,他不会霸占这个线程,而导致死锁。而同时,由于这个锁死这个acquiresleep独有的,因此,其他线程不会去acquire这个锁,不会导致死锁。
lesson 15
如果在一个文件操作到一半的时候突然发生断电等情况,那么就可能会导致文件系统的损坏。
对于某一个文件操作,对于其中的每一次写操作,我们先写一个总操作次数,这是原子的,然后在将剩下的一条一条都先写到log中。这样,即便只输出了一半,也能因为知道总条数而知道没写完而丢弃。在全部写完后,才一步一步执行,然后清除log。
如果没有commit log就当作没写完,如果commit了但是没有被清除就将install全部重新做一遍。因为写操作多做几遍是没什么问题的。
整体流程:
begin_op():如果log还有空间并且不在提交中,那么就将剩余未提交数量+1,否则开睡。
log_write:判断是否是正常的一次写,然后开写。如果是和前面有重合的写block,就去掉这一次写,如果是要新写一块,那就记录,并且给这一块打上标记。
end_op():剩余未提交数量-1,如果一波操作完成了,即没有剩余未提交数量了,那么就开始提交,否则日子空间就可以空出来有下一个文件操作继续了,因此唤醒begin_op。
然后开始commit:
在log_write之外就已经将相应的data部分写入了cache,而log_write中就是写一下对应的blockno。
接着,首先write_log,将data从cache写到了log中。接着write_head,将cache中的blockno,也就是head写到super block中,完成了commit,接着install_trans,将data从log写到真正对应的block中。最后将cache大小设为0。再次write_head,也就大概把super block给清空了,也就是把commit给清空了。install_trans和write_head看似在做重复操作,从from写到to,然后再反过来写一遍,当实际上,他的to是cache对应在真正磁盘上的位置,from是cache的位置,因此并不重复。
为了保证block对应的cache不要被清空,就需要pin一下它,因此在log_write中pin一下,然后在install_trans完之后已经写入磁盘了,就可以unpin了。
在recover的时候直接看眼superblock是否有东西,有东西就install一下就可以了,只不过这些就不用unpin了。因为这些东西已经被复制到log也就是磁盘中了。实际上是用于保证已经写入log的block不会被撤回。
其中也有很多部分特意防止了wakeup lost。
并且需要注意的是,在判断能不能继续begin_op的时候,同时计算了已经写入的和outstanding,outstanding是正在执行transaction的cpu数,也就是可能有多个cpu同时在做事务。而同时做事务需要的log空间就更大,因此需要对当前并行数量做限制。
当且仅当所有的事务都做完后才会commit。
lesson 16
ext3相较于ext2修改了journal,也就是logging。
-
可以异步,也就是系统调用结束的时候没必要一定应用写入。而这会导致系统调用的返回并不能代表它的完成情况,因此需要对文件的有一个同步的函数,即将在它上面做的所有的更改都应用掉。也就是fsync。
这需要log通过存储代表每一个系统调用的handle来监督。
-
每隔一段时间开一个大的事务,在这段时间内的读写操作都放在这个大的事务中。可以减少事务的固定损耗,如log,更有可能write absorption,并且有更好的disk scheduling,即一次性写入大量的数据。
-
并行。增加事务并不会由锁导致串行,都是并且允许有多种不同状态的事务同时存在。
在提交的时候,不允许新的调用,等待所有已有调用,更新数据,并开启一个新的transaction,和普通log一样更新数据。
log空间的使用就类似于循环队列,commit完了就可以pop掉,空出空间。
由于包含了多个transaction,因此恢复的时候需要确认其log中真正有用的部分,ext3是用魔法数字和每个transcation会记录一个长度来判断的。
要求transacation必须先等其中所有系统调用都完成后才能开启下一个transaction是因为transaction之间可能互相影响,但只要影响了就应该要在一个事务中完成。
lesson 17
Trap-and-Emulate 的工作原理
- VMM的角色:
VMM 作为宿主机操作系统的一部分,充当 Guest 操作系统和硬件之间的中介。
VMM 本身运行在 Supervisor mode,而 Guest 操作系统则运行在 User mode。
VMM 通过 trap 机制来捕获 Guest 操作系统中的 privileged 指令(例如修改 SATP 寄存器)并进行模拟。
- 指令截获(Trap):
当 Guest 操作系统执行任何需要 Supervisor mode 权限的指令时(例如修改 SATP 寄存器),该指令将触发一个 trap。
这个 trap 将把控制权交给 VMM,VMM 会模拟这条指令,并返回 Guest 操作系统。
- 指令模拟(Emulate):
VMM 会为每个 Guest 操作系统维护一套虚拟的寄存器状态(例如 SEPC、STVEC 等)。
当 Guest 操作系统执行需要读取 privileged 寄存器的指令时,VMM 会模拟该操作,提供一个虚拟的寄存器值。
- 虚拟状态信息:
VMM 维护每个 Guest 的虚拟状态,包括虚拟寄存器、虚拟的 mode(用户模式还是内核模式)等。
VMM 会在 Guest 进程切换时更新这些状态信息,以确保虚拟机的正确执行。
为什么不能直接使用硬件中的寄存器
虽然硬件中有对应的寄存器,但 VMM 需要模拟这些寄存器的行为,因为:
当 Guest 操作系统尝试读取或修改 privileged 寄存器(如 SCAUSE 寄存器)时,硬件会将其标记为非法操作(例如访问权限不够)。VMM 需要调整这一行为,以提供 Guest 操作系统期望的行为。
为了避免暴露宿主机的真实硬件状态,VMM 需要使用虚拟寄存器,确保 Guest 操作系统只看到它应该看到的值。
Page Table 和 Shadow Page Table
Page Table 管理:
VMM 需要管理 Guest 操作系统的 Page Table,并确保其映射正确。
当 Guest 操作系统尝试修改 SATP 寄存器时,VMM 会拦截这个操作,生成一个虚拟的 Shadow Page Table,并将其设置到宿主机的 SATP 寄存器中。
Shadow Page Table 通过将 Guest 的物理地址(GPA)映射到宿主机的物理地址(HPA)来实现内存隔离。
Shadow Page Table 的重要性:
由于 Guest 操作系统无法直接访问宿主机的真实物理内存,VMM 会创建一个 Shadow Page Table,用来映射 Guest 操作系统的虚拟地址到宿主机的物理地址。
这样,Guest 操作系统只能访问它被允许的内存区域,而无法逃逸到宿主机的内存空间。
VT-x硬件虚拟化支持
VT-x通过提供硬件支持,简化了虚拟机的运行,并大幅提高性能。在传统的Trap and Emulate模型中,VMM需要为每个虚拟机(Guest)保存虚拟状态信息,而VT-x将这些状态信息保存在硬件中,使得特权指令的执行不再需要通过trap进入VMM。这样,Guest可以在不触发trap的情况下执行特权指令,从而提高了执行效率。
虚拟寄存器与控制寄存器
-
Guest和Host模式:在VT-x的架构中,虚拟机有两个模式:Guest mode(non-root mode)和Host mode(root mode)。Guest模式下的虚拟寄存器保存着虚拟化状态,而Host模式下使用的是真实的控制寄存器。硬件通过独立的虚拟控制寄存器,允许Guest操作系统直接修改这些寄存器,而无需经过VMM的干预。
-
VMM与VMCS:VMM通过创建虚拟机控制结构(VMCS),在硬件中配置虚拟机的状态并通过指令(如VMLAUNCH和VMRESUME)启动或恢复虚拟机。
进程与虚拟机的区别
进程的隔离:Dune论文通过利用VT-x硬件,允许普通的Linux进程在不完全依赖操作系统虚拟化的情况下,享受虚拟化隔离。这使得进程可以有自己的虚拟化控制寄存器(如CR3),并允许更细粒度的内存控制(如垃圾回收的加速)。
Dune与VT-x的创新
Dune利用VT-x硬件的虚拟化功能,不仅支持虚拟机,还能让普通进程享受虚拟机的内存隔离和安全特性。例如,它允许一个进程运行未被信任的插件,隔离插件与主进程的内存空间,确保插件不能恶意访问主进程的资源。
其他关键概念
- EPT(Extended Page Table):通过EPT,VMM可以控制Guest使用哪些物理内存,防止Guest直接访问不允许的内存区域。EPT为每个虚拟机提供二次地址转换,将Guest虚拟地址转换为主机物理地址。
lesson 20
相较于高级语言,c能用汇编,并发与内核所需的并发类似,无法直接访问内存,并且更快。但是,用golang这个高级语言实际上进行的时间也只慢了15%左右,也是可以接受的。
lesson 22
核心技术:预测执行和缓存
预测执行
预测执行是现代CPU为了提高性能而采用的一种技术,允许CPU在确定分支的条件之前,提前执行某些指令。当CPU发现分支指令时,它会基于过去的执行历史进行预测,提前执行预测的路径。即便预测错误,CPU也能回滚错误的执行,恢复到正确的状态。
在Meltdown攻击中,攻击者利用这一点,通过让CPU提前加载某个内核内存地址的数据,即使该地址不可访问。然后,当预测执行“回滚”时,攻击者依然可以通过测量缓存中的数据来推测出原本无法访问的内核数据。
CPU缓存
当CPU从内存中读取数据时,通常会将数据存储在不同级别的缓存中(如L1、L2、L3缓存)。这加速了后续对同一数据的访问。在Meltdown中,攻击者通过读取内核内存中的某些数据,利用CPU缓存机制,通过分析缓存中的内容推断出内核数据,尽管攻击者没有直接权限访问这些数据。
虽然Meltdown攻击利用了硬件层面的漏洞,但操作系统和硬件厂商已经通过多个途径进行修复。主要修复方法包括:
禁止预测执行访问内核数据:更新的CPU微架构不允许在预测执行时访问未经授权的内存地址。
内核页表隔离(KPTI, Kernel Page-Table Isolation):操作系统修改了内核的页面表映射,将内核空间和用户空间完全分开,防止了用户空间代码意外访问内核数据。
lesson 23
RCU(Read-Copy-Update)通过允许读线程在没有任何锁的情况下读取数据来解决了读写锁的这些性能瓶颈。RCU的关键思想是不修改现有的数据,而是创建数据的一个副本进行修改。写操作会替换整个数据结构(如链表节点),而不是直接修改现有节点的数据。这样,读线程可以继续访问未修改的旧版本数据,从而避免了对读线程的阻塞。
具体例子:
• 场景一:数据元素内容更新:当一个写线程想要修改链表元素时,RCU会创建一个新的链表元素,将新数据写入这个新元素,然后更新链表的指针指向新的元素。原始数据仍然可供读线程访问,直到所有的读线程完成对旧数据的访问。
• 场景二:插入数据:写线程将新节点插入到链表中,但并不直接修改链表中的现有指针。写线程会创建一个新的节点,并且确保在更新链表头指针时,所有的数据更新都是一致的。
• 场景三:删除数据:删除链表元素时,写线程不会立即释放旧的节点,而是标记其为已删除。读线程继续读取旧数据,直到所有读线程都完成后,删除操作才会被实际执行。